
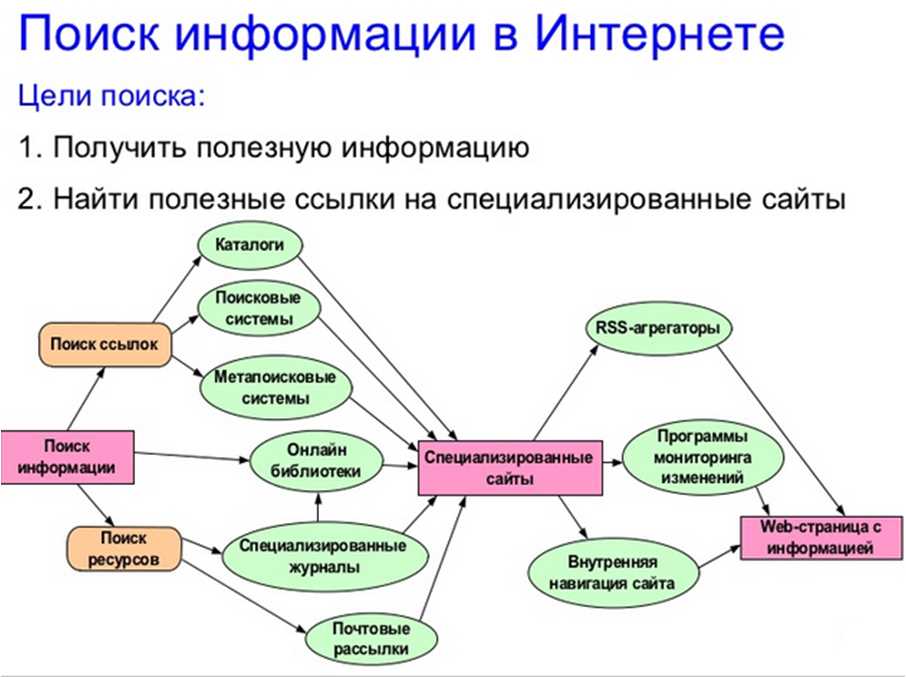
Сервис по созданию сайтов поисковых систем позволяет регистрировать, создавать и настраивать индексацию сайтов с использованием продвинутого алгоритма индексации. Мы знаем, что результаты поиска имеют ключевое значение, поэтому мы помогаем в настройке крошечной базы данных для индексации.
Мы понимаем, как важно, чтобы ваш сайт был зарегистрирован корректно. Поэтому наш обработчик crawler смотрит на вашу базу данных с примерами предложений и помогает настроить наиболее эффективные критерии поиска.
Как создать собственную поисковую систему с помощью CSE. Урок продвинутого сорсинга
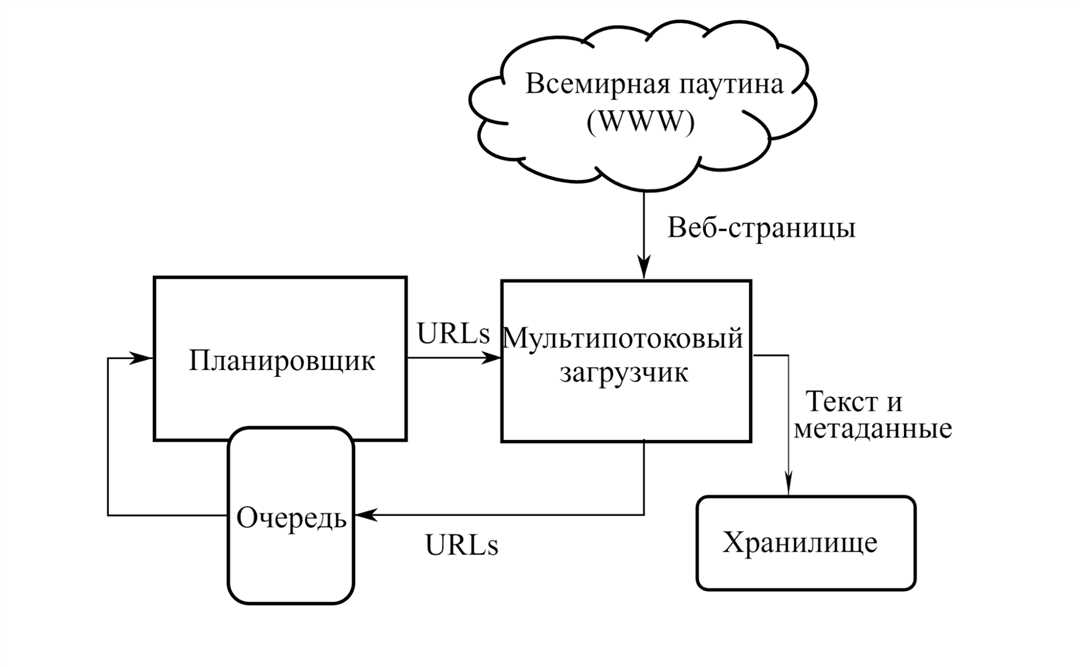
Для того чтобы создать собственную поисковую систему с использованием CSE, вам необходимо пройти через несколько шагов:
- Протестировать и изучить основные функции поисковика.
- Настроить файл robots.txt для правильной индексации.
- Использовать fetch и import для загрузки данных в индекс поисковой системы.
- Настройка среды разработки для работы с CSE.
- Ознакомиться с принципами продвинутого сорсинга, такими как использование Seneca.
После выполнения этих шагов вы сможете создать собственную поисковую систему с использованием CSE и приступить к настройке ее работы под свои задачи и требования.
Как сделать поисковую систему с ИИ, используя FastAPI, Qdrant и ChatGPT
Для создания поисковой системы с ИИ, вам понадобится использовать FastAPI, Qdrant и ChatGPT. Начнем с установки необходимых зависимостей:
- Установите FastAPI, используя команду:
pip install fastapi. - Для работы с ChatGPT скачайте необходимую библиотеку.
- Qdrant позволит оптимизировать поиск. Скачайте сервис и настройте его для работы с FastAPI.
После установки зависимостей, вам необходимо получить openai_api_key для использования ChatGPT и предварительно обученных моделей для поиска.
Создайте файлы для хранения данных и индекса поисковой системы. Определите необходимые поля для хранения значимых данных и сниппета поискового результата.
Для продвинутого урока по созданию поисковой системы нужно знать следующее:
1. Сначала необходимо создать файл env-example, в котором будут храниться все настройки окружения. Этот файл содержит необходимые переменные для правильной работы поисковика.
2. Для полноценного функционирования поисковой системы необходимо использовать только full route, который позволяет пользователю просматривать полные страницы, на которых найден искомый запрос.
3. Для реализации рейтинга и индексации страниц поисковой системы обратим внимание на поле index, где будут храниться данные о релевантности контента.
Разработка крошечной поисковой системы с помощью ChatGPT

Для создания крошечной поисковой системы с использованием ChatGPT необходимо настроить локальную среду. Для этого создайте файл env-example, в котором укажите все необходимые переменные окружения.
Далее, приступим к написанию кода для ранжирования результатов поиска. Мы можем использовать различные алгоритмы ранжирования, чтобы выдать пользователю наиболее релевантные результаты по запросу.
Примеры кода для работы с ChatGPT и ранжированием результатов можно найти в документации и на сторонних ресурсах. Важно учесть особенности среды выполнения и алгоритмы работы с файловой системой для оптимальной производительности системы.
- Настройка локальной среды
- Примеры кода для работы с ChatGPT
- Алгоритмы ранжирования результатов
Настройте свою локальную среду для работы с сервером поисковой системы. Для этого скачайте и установите необходимые программные компоненты, чтобы иметь возможность создать собственную поисковую систему. Для начала, загрузите необходимые файлы с GitHub, содержащие инструкции и информацию по работе с сервером поисковой системы. После этого проиндексируйте все файлы, чтобы иметь актуальный индекс для вашей поисковой системы.
Настройка Qdrant и OpenAI не такая сложная задача, как может показаться на первый взгляд. Вам понадобится среда, в которой были бы установлены необходимые зависимости и библиотеки. Главное преимущество OpenAI заключается в его готовых моделях Текста, голоса и многих других. Если вы создали собственную поисковую систему на CSE, вам придется обойти момент их интеграции с Qdrant. OpenAI предоставляет готовые API-интерфейсы, с помощью которых вы сможете использовать его модели интеллектуального поиска.
Он предоставляет доступ к расширенным функциям, таким как fetch & index API, который позволяет работать с внешними источниками данных. С помощью Qdrant можно создать поисковую систему, в которой данные будут indexed на основе векторов и запросы будут работать с высокими показателями эффективности.
OpenAI
OpenAI — это компания, стремящаяся создать и распространять искусственный интеллект (ИИ) в масштабах всего человечества. Они пишут алгоритмы и инструменты, которые помогают сделать ИИ более доступным и понятным для обычных пользователей. OpenAI также создали OpenAI GPT-3, самую большую и мощную модель языкового представления до сегодняшнего дня.
Компания OpenAI indexed огромное количество информации из всемирной паутины, чтобы образовать собственную базу данных. Дальше, в целях улучшения функционала, они создали удобную среду, где вы сами сможете взаимодействовать с их ИИ-системой.
При пользовании сервисом OpenAI вам предоставляется возможность использовать различные классы функций и методов, которые помогут вам в обработке и работе с вашей информацией. Вы сможете обратиться к экспертам, если у вас есть вопросы или возникли проблемы.
С помощью OpenAI вы будете иметь доступ к последним достижениям технологий ИИ, что позволит вам существенно улучшить свой проект или продукт. Благодаря алгоритмам и подходам, разработанным командой OpenAI, вы сможете максимально эффективно использовать информацию и ускорить свой рабочий процесс.
Работа с OpenAI — это шаг в будущее, где с помощью ИИ возможны неограниченные возможности для работы с данными и информацией. Попробуйте использовать сервис OpenAI и убедитесь в его мощи и удобстве.
Извлечение данных
При создании поисковой системы с использованием OpenAI и других инструментов, извлечение данных становится более сложным и требует грамотного подхода. Особенно важно правильно обрабатывать запросы пользователей, чтобы появился рейтинг результатов.
Часто для извлечения данных используются специальные алгоритмы и структуры данных, такие как struct_index, которые помогают эффективно обрабатывать информацию и делать поисковые запросы более успешными.
Одним из важных этапов при извлечении данных является анализ заголовков, текста и других элементов страниц, чтобы определить их релевантность и значимость для пользователя. Это позволяет повысить качество результатов поиска и улучшить опыт пользователей.
Искусственный интеллект, такой как openai, играет значительную роль в процессе извлечения данных, помогая автоматизировать некоторые этапы работы и улучшить точность поисковых запросов.
Итак, извлечение данных является важным этапом в создании поисковой системы, и его правильная реализация с помощью современных инструментов и технологий позволит повысить эффективность работы поиска и улучшить пользовательский опыт.
Векторизация и индексация данных
Для эффективной обработки поисковых запросов и ускорения поиска необходимо векторизировать и индексировать данные. Для этого создали структуру данных, которая хранит значимые элементы страницы. Эти элементы могут быть абзацами, заголовками, ссылками и т.д.
Векторизация данных заключается в преобразовании содержимого страницы в векторные представления. Это позволяет сравнивать и анализировать страницы с помощью математических операций.
Индексация данных отвечает за сохранение информации о страницах и их содержимом. Она помогает при поисковых запросах быстро найти нужные результаты. Для этого нужно создать индекс по всему контенту сайта.
Дальше следует разработка алгоритмов обработки данных, чтобы оптимизировать процесс поиска. Обработка запросов происходит на основе созданного индекса, что позволяет находить соответствия между запросом пользователя и содержимым страниц.
Помощь свой поисковой системе со значением векторизации и индексации данных существенна. Необходимо правильно настроить обработку данных, чтобы пользователь мог быстро и удобно получить нужную информацию.
Для создания сервера с FastAPI необходимо приступить к индексации данных. Сначала необходимо определить структуру данных для индекса, которые мы будем использовать для запросов. Это может включать в себя уникальные идентификаторы, ключевые слова, описания и другие важные данные из источников.
Далее мы разрабатываем индексатор, который будет загружать и обновлять данные в нашем индексе. Важно настроить окружение (env-example) и убедиться, что все необходимые библиотеки установлены корректно.
После индексации данных, необходимо разработать алгоритм ранжирования для запросов. Определяем критерии ранжирования и выбираем подходящие алгоритмы для расчета рейтинга. Этот процесс включает в себя оценку релевантности данных и присвоение им соответствующего рейтинга.
Также стоит уделить внимание обработке сниппета — небольшого фрагмента информации, который отображается пользователю в результатах поиска. Это поможет улучшить опыт пользователя и повысить релевантность результатов.
В процессе разработки сервера с FastAPI также следует учитывать критерии, которые будут использоваться для выполнения поисковых запросов. Важно тестировать функционал и убедиться, что сервер работает стабильно при различных условиях нагрузки.
Как и зачем я создал свой поисковик Pick история создания и примеры кода
Один из ключевых элементов любой поисковой системы является ее способность обрабатывать и анализировать огромные объемы данных. В своем проекте я поставил перед собой цель создать собственный поисковик Pick, способный эффективно индексировать и выдавать результаты поиска для пользователей. Для этого я использовал ряд технологий, среди которых poetrylock, с помощью которой я управлял зависимостями проекта для надежности и безопасности. Также, для создания сервера поисковой системы, я применил инструмент FastAPI, который позволил мне быстро развернуть сервер и обрабатывать запросы пользователей. Дальше, для более эффективной обработки данных я использовал типизацию данных с помощью type hints и преобразовывал итератор в массив с помощью функции iterator_to_array.
Как создавался Pick:
- Сначала была создана база данных SQLite с таблицей, содержащей необходимые поля для индексации URL.
- Был создан python-класс Indexer, который выполняет индексацию ссылок, извлекая нужную информацию.
- Был написан метод для регистрации сервиса индексации, который принимает аргументом URL и добавляет его в базу данных.
- Теперь при добавлении URL, Indexer извлекает полезную информацию (например, заголовок и ключевые слова) и сохраняет ее в базе данных.
- Для обработки индекса был создан объект типа Index, который содержит информацию о категориях, словах, их весе и т.д.
- Для алгоритма ранжирования был реализован метод, который оценивает значимость каждой строки из базы данных с учетом важности слов и других факторов.
- Основная строка поисковика, pick, создает объект типа Indexer и поддерживает взаимодействие с базой данных и методами обработки запросов.
Будущее pick зависит от эффективности алгоритма ранжирования и сбора полезной информации для индексации.
Создаем индекс в базе данных
Для создания поисковой системы необходимо создать индекс в базе данных. Для этого мы используем функцию iterator_to_array, которая преобразует результат запроса в массив данных.
Далее необходимо определить источник данных, который будет использоваться для индексации. Это может быть структурированный курс, набор статей или даже собственное творчество, такое как стихи или проза.
При создании своей поисковой системы важно определить ключевые аспекты данных, которые будут индексироваться. Для этого необходимо определить наиболее релевантные и важные элементы информации о каждом элементе.
Когда индекс создан, необходимо настроить маршрут (route), который будет отвечать за обработку данных и поиск по ним. В этот маршрут будут передаваться запросы от пользователей, которые будут обрабатываться для получения результатов поиска.
Регистрируем сервис индексации и страницу поиска:
| 1 | Создаем файл poetry.lock для фиксации версий библиотек: |
| 2 | Инициализируем индексацию с помощью команды index: |
| 3 | Теперь знаем, как создать страницу поиска: |
| 4 | Можно идти дальше и настраивать следующие запросы: |
| 5 | Для обновления данных используем update и продолжаем работу. |
Индексатор URL Picker
Для обработки индексации страницы основной код будет импортировать Iterator_to_array из своей среды. Зачем это нужно? Данный код позволит преобразовать итератор в массив, чтобы обеспечить удобную обработку данных.
Далее, с помощью цикла foreach мы будем обрабатывать каждую страницу, прогоняя ее через индексатор. Это необходимо для того, чтобы добавить URL страницы в индекс поисковой системы и обновить соответствующие данные.
Важно также следить за заголовками (headers), которые могут содержать информацию о статусе страницы, а также за другими метаданными.
Индексатор URL Picker будет осуществлять процесс обработки URL, добавляя их в индекс и обновляя необходимую информацию для дальнейшего поиска.
Как поддержать robots.txt?
Для создания этого файла просто создайте новый текстовый файл с именем robots.txt и разместите его в корневой директории вашего сервера. Этот файл поможет роботу поиска понять, какие страницы необходимо индексировать, а какие — нет. В этом файле можно указывать адреса, которые необходимо исключить из индексации.
Настроить robots.txt для вашего сервиса поиска — это не сложно, но очень важно для создания правильной стратегии индексации и ранжирования страниц. Помните об этом при создании своей собственной поисковой системы.
Обработка индекса
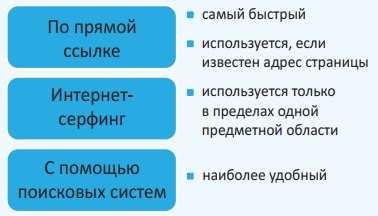
Кроме того, обработчик индекса поисковой базы может быть настроен для работы с различными источниками данных. Например, он может работать с веб-страницами, извлекая информацию из HTML-кода сайтов. Такой подход позволяет создавать собственный поисковый движок, который будет работать не только с уже добавленными в базу данных сайтами, но и с новыми сайтами, которые будут добавлены позже.
Работа обработчика индекса поисковой базы может быть интегрирована с другими сервисами, например, с LinkedIn или другими социальными сетями. Это открывает новые возможности для пользователей, позволяя работать с различными источниками данных и получать более полную информацию при поиске.
Итак, создаем обработчик индекса поисковой базы — просто необходимый компонент для крошечной поисковой системы или CSE. Извлечение данных, работа с запросами и ранжирование результатов — все это становится доступным благодаря правильно настроенному обработчику индекса поисковой базы.
Выполняем поисковые запросы
Для эффективного выполнения поисковых запросов можно использовать шкалу релевантности результатов. Это позволит оценить соответствие результатов запросу пользователя и вывести наиболее подходящие источники информации.
Важно организовать процесс выполнения запросов таким образом, чтобы пользователь получал актуальные и точные результаты. Сейчас существует множество различных источников данных, которые могут быть использованы для создания качественной поисковой системы.
При выполнении поисковых запросов важно учитывать различные типы данных, такие как текстовые данные, файлы и др. Для работы с данными в Python можно использовать функции iterator_to_array для преобразования данных в массив.
Алгоритм ранжирования
Одним из важнейших аспектов алгоритма ранжирования является учет релевантности страницы к запросу пользователя. Это может быть достигнуто путем анализа ключевых слов на странице, внешних ссылок, обработки метаданных и других факторов. Также алгоритм должен учитывать популярность страницы, ее авторитетность и актуальность для конкретного запроса.
Для обработки ранжирования поисковая система использует специальный обработчик, который анализирует и сортирует полученные данные с учетом установленных правил и алгоритмов. Важно, чтобы этот обработчик был оптимизирован для быстрой обработки больших объемов информации и давал точные и актуальные результаты.
Пишем обработку сниппета: настройка страницы Pick для отображения результатов запросов
При разработке своей поисковой системы Pick важным этапом является настройка страницы, на которой пользователи будут видеть результаты своих запросов. Для этого необходимо правильно обработать сниппеты, чтобы пользователь мог сразу найти нужную информацию.
С помощью FastAPI и Picker мы можем настроить отображение результатов поиска так, чтобы пользователь получал нужные сведения сразу. Например, мы можем отображать только самые релевантные ссылки или файлы, которые соответствуют запросу пользователя.
При создании обработки сниппета важно учесть, что пользователи привыкли к структуре результатов поиска, как на Google. Поэтому важно, чтобы информация была четко представлена и удобна для восприятия.
Настройка страницы Pick для отображения результатов запросов позволит пользователям эффективно использовать поисковую функцию и быстро находить нужные сведения.
Будущее Pick
В дальнейшем планируется добавить возможность обработки различных типов файлов, улучшить механизмы формирования заголовков и метаданных страницы, а также осуществить интеграцию с сервисами Google для расширения функционала поисковой системы Pick.
Также в планах разработать возможность создания собственных источников данных, как локальных, так и внешних, что позволит пользователям более гибко настраивать параметры поиска и получать более точные результаты. Благодаря внедрению векторной модели обработки запросов и ранжирования результатов поиска Pick будет обеспечивать более точные и релевантные результаты для пользователей.
Как создать свою поисковую систему?
Для создания собственной поисковой системы вам необходимо провести ряд шагов, включающих в себя индексацию URL-адресов, ранжирование страниц и обработку поисковых запросов. Убедитесь, что вы настроили свою среду разработки и можете взаимодействовать с зарегистрированным сервисом OpenAI.
Сначала создайте механизм индексации, который позволит вашей системе анализировать содержимое URL-адресов и сохранять информацию о них для дальнейшего поиска. Разработайте алгоритм ранжирования, который определит порядок отображения результатов поиска пользователю в зависимости от их релевантности.
Далее необходимо настроить страницу поиска, которая будет взаимодействовать с вашей базой данных и предоставлять результаты поисковых запросов пользователям. Обработка запросов должна быть оптимизирована с учетом скорости и эффективности.
Не забудьте о правильной обработке сниппетов, которые будут отображать пользователю краткую информацию о найденных результатах. Будущее вашей поисковой системы зависит от правильного подхода к разработке и постоянного улучшения функционала.