
В современном информационном обществе быстрый доступ к актуальным данным является ключевым фактором успешного функционирования любого бизнеса. Однако, найти нужную информацию на просторах интернета может быть долгим и трудоемким процессом.
Именно поэтому наша команда разработала собственное программное обеспечение, которое позволяет автоматизировать процесс сбора информации с веб-сайтов. Благодаря нашему уникальному решению вы сможете получить необходимые данные в удобном формате, максимально экономя ваше время и ресурсы.
Наше программное обеспечение предоставляет возможность:
- извлекать адреса и контактные данные организаций и частных лиц;
- получать материалы и статьи по заданным критериям;
- собирать информацию о товарах и услугах предложенных на сайтах;
- извлекать рубрику, дату публикации и другие сведения;
- и многое другое.
Наше программное обеспечение гибкое и настраиваемое. Вы можете использовать его для анализа конкурентов, мониторинга рынка, создания баз данных и многих других задач. Все настройки и параметры программы можно легко установить с помощью понятного интерфейса.
Сделайте первый шаг к упрощению работы с информацией уже сегодня! Позвольте нашему уникальному парсеру сайтов сэкономить ваше время и силы, освободив вас от монотонных и рутинных задач сбора данных.
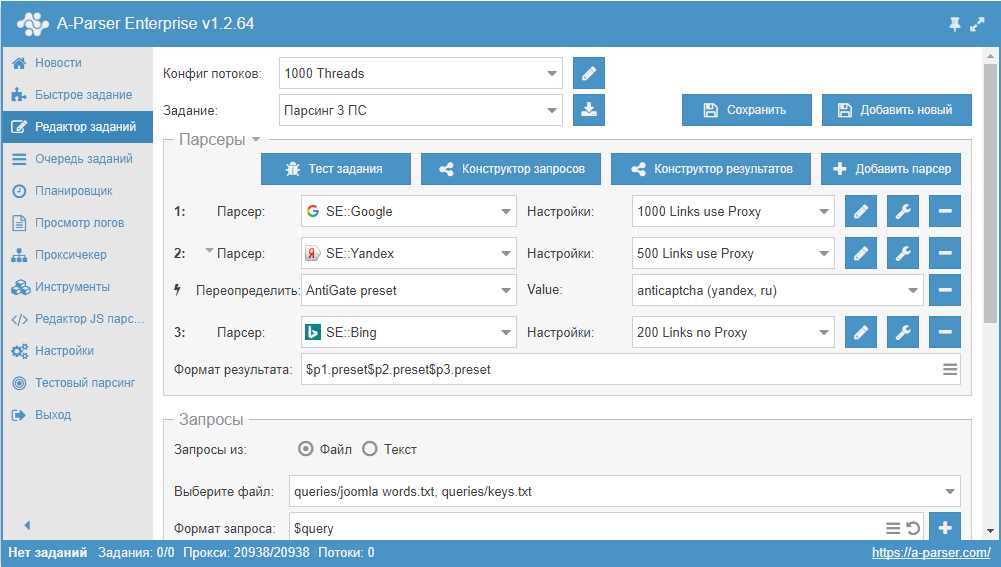
Делаем парсер чтобы массово тянуть с сайтов что угодно
Для выполнения данной задачи вам понадобится использовать Python, мощный и гибкий язык программирования. Он предоставляет широкие возможности для разработки парсеров, простой и очень эффективный инструмент, который позволит автоматически извлекать интересующую вас информацию с веб-сайтов.
Одной из важных задач, которую нужно решить при создании парсера, является осуществление массового сбора информации с разных страниц. Это означает, что ваш парсер должен находить все нужные вам страницы, обходить их и извлекать необходимые данные.
Для того чтобы массово тянуть с сайтов различную информацию, можно использовать различные техники и инструменты. Например, библиотеку BeautifulSoup, которая поможет вам легко извлекать нужные данные из HTML-кода веб-страниц. Используя инструменты, такие как soup.find(), soup.find_all() и другие методы, вы будете иметь возможность получать сырой текст с веб-страницы.
Далее необходимо произвести очистку собранного текста. Для этого можно использовать различные методы и функции, которые помогут удалить ненужные символы, теги и прочие элементы. После очистки текста можете сформировать функцию для дальнейшей работы.
Получив все нужные данные, вам потребуется собрать адреса всех страниц, которые вы хотите использовать для парсинга. Для этого можно использовать различные методы и приемы, например, вручную выбрать страницу для отладки и получить сырой текст с этой страницы.
Что дальше? Теперь самое время сохранить полученные данные в файл. Выберите нужный вам формат и запишите собранную информацию в него. Это позволит вам удобно хранить и использовать собранные данные в дальнейшем.
Таким образом, учиться «парсить» сайты или написать свой первый парсер на Python — это важный и полезный навык, который поможет вам получать актуальную информацию и используя ее в своей работе. Теперь вы сможете массово извлекать с сайтов то, что вам нужно!
Что делаем
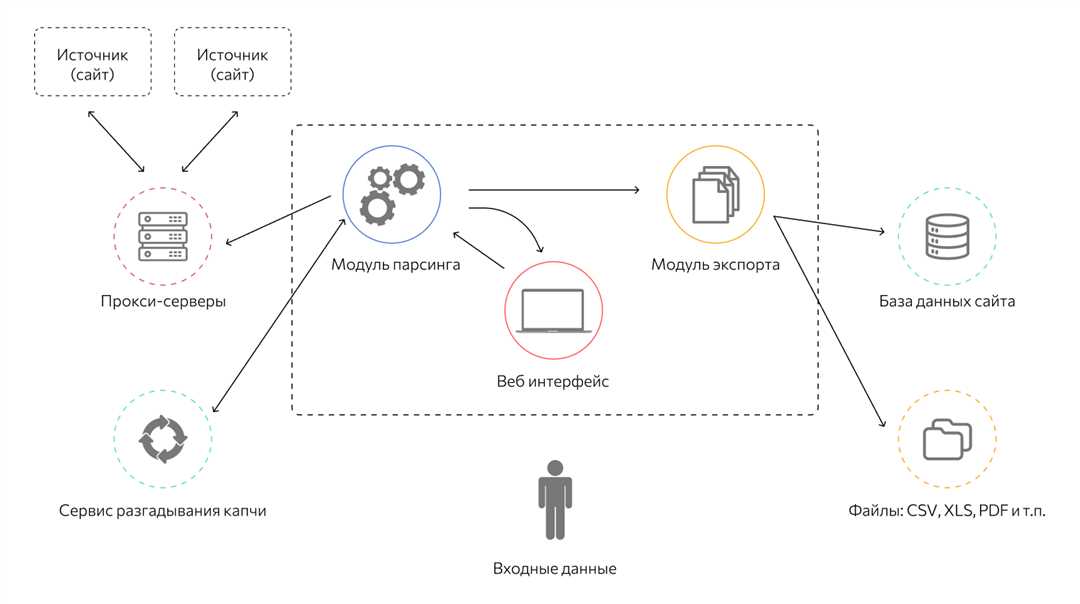
Наша команда специалистов занимается разработкой инструментов для удобного и эффективного парсинга нужной информации с веб-сайтов. Мы помогаем клиентам извлечь нужные данные с различных сайтов, сэкономить время и силы на ручной обработке информации.
Мы предлагаем нашим клиентам парсеры, которые способны извлекать нужную информацию из большого объема текста, запросов или cookie. Наша уникальная технология позволяет обрабатывать даже самые сложные случаи. Опираясь на предоставленное описание задачи и требования клиента, мы разрабатываем итоговую парсерную функцию.
Для начала работы клиенту необходимо выбрать страницу для отладки, на которой находится нужная информация. Мы предоставляем инструкции по настройке парсера, которые позволяют получить сырой текст, чистый от ненужных элементов. Затем мы собираем функцию, которая позволяет получить адреса всех страниц, где находится нужная информация.
После получения и обработки всех необходимых данных, мы сохраняем текст в файл, предоставляемый клиенту в удобном для него формате. Мы также предоставляем информацию о способе запуска парсера и настройке выгрузки данных в определенный тип файла.
Наши парсеры основаны на принципах извлечения информации с использованием Xpath. Мы предоставляем краткий урок по использованию этого инструмента, примеры работы с HTML-файлами. Мы также разъясняем, как извлекать нужные теги через XPath с помощью предикатов и определять структуру сайта. Мы рассказываем о двух типах пагинации, рассматриваем процесс парсинга сайтов с разной структурой.
Нашей целью является предоставление клиентам полной информации о создании парсера, начиная с его настройки и заканчивая запуском и использованием. Вместе с нами вы сможете получать необходимую информацию и извлекать нужные данные с веб-сайтов с помощью парсера.
Выбираем страницу для отладки
В данном разделе мы рассмотрим процесс выбора конкретной веб-страницы для дальнейшей отладки и тестирования нашего парсера. Это важный этап, который поможет нам проверить работоспособность и эффективность парсинга данных.
При выборе страницы для отладки необходимо учитывать некоторые моменты. Во-первых, нужно найти страницу, содержащую информацию, которую нам нужно извлечь. Для этого мы можем использовать поисковые запросы, ключевые слова или просматривать различные категории и субъекты.
Когда мы нашли подходящую страницу, следующим шагом будет получение ее адреса. Мы можем скопировать адрес из адресной строки браузера или воспользоваться функцией сохранения адреса в файл, чтобы использовать его позже.
Получив адрес страницы для отладки, мы можем приступить к раскрытию содержимого страницы. Для этого мы используем различные инструменты и настройки парсера. Одним из таких инструментов может быть Beautiful Soup, который поможет нам обработать HTML-код страницы и извлечь нужные нам данные.
Важно отметить, что настройки парсера могут быть разными в зависимости от конкретной страницы. Мы можем настроить извлечение полей для конкретного продукта или получить ссылки на карточки товаров из определенной категории. Для этого мы можем использовать различные методы, например, XPath, чтобы точно указать, какие элементы на странице нужно выбрать.
После того, как мы настроили парсер на нужные нам элементы страницы, мы можем запустить его и получить результаты. Парсер выполнит запросы к странице, получит данные, и мы сможем сохранить их в нужный тип файла (например, CSV или JSON).
Таким образом, выбор страницы для отладки — важный шаг в разработке парсера. На этом этапе мы проверяем работу парсера на конкретном примере, а затем можем применить его к другим страницам с аналогичной структурой.
Получаем сырой текст
В этом разделе мы рассмотрим, как исполнитель, занимающийся разработкой парсеров для сбора информации с веб-сайтов, может получать сырой текст с веб-страницы.
Получение сырого текста является первым шагом в обработке данных. Вместо того чтобы вручную копировать и вставлять текст с каждой страницы, мы можем использовать код для получения и автоматической обработки текста со всех страниц веб-сайта.
Когда мы получаем доступ к веб-странице с помощью парсера, мы можем использовать различные методы и инструменты для извлечения содержимого страницы. Благодаря использованию библиотеки beautifulsoup в Python, мы можем получить сырой текст веб-страницы.
Для получения сырого текста нам потребуется подключение к веб-странице через URL. Мы используем модуль urllib.parse для формирования URL-адреса и передачи необходимых параметров для получения данных. Затем мы перейдем на страницу, которую хотим обработать.
При получении данных с веб-страницы мы можем использовать различные методы обработки текста. Например, мы можем применять правила разбора текста для удаления ненужных элементов или форматирования текста.
Каждый веб-сайт имеет свою структуру и элементы, и мы должны учитывать эти особенности при обработке текста. Например, если у нас есть страница с новостной статьей, мы можем использовать методы разбора текста, чтобы удалить лишние элементы, такие как баннеры, рекламу или другую информацию, не относящуюся к самой статье.
Используя методы и инструменты обработки текста, мы можем создать функцию, которая будет автоматически получать сырой текст с веб-страницы. Это позволит нам эффективно обрабатывать большое количество данных и ускорить бизнес-процессы, связанные с анализом информации с веб-сайтов.
Также, при использовании собственного парсера, мы имеем полные права на использование полученных данных в соответствии с пользовательским соглашением сайта. Это гарантирует трансграничную обработку и использование данных на территории России и за ее пределами.
Итак, в этом разделе нашего рекламного поста мы познакомились с процессом получения сырого текста с веб-страницы. Узнали о важности корректного кода и использования соответствующих инструментов для обработки данных. Следующий шаг — извлечение информации из текста для дальнейшего анализа и использования в бизнес-процессах.
Чистим текст
Для доступа к содержанию страницы и извлечения необходимой информации используются различные инструменты. Один из них — библиотека BeautifulSoup, которая позволяет решить множество задач по обработке HTML и XML файлов.
При парсинге страницы, сначала получаем сырой текст, который содержит различные теги и форматирование. Затем, с помощью библиотеки BeautifulSoup, производим очистку текста от ненужных тегов и символов.
Для этого сначала создаем объект soup, указывая полученный сырой текст как аргумент. Затем, с помощью soup, можно найти и удалить ненужные теги и содержимое страницы.
Очищенный текст можно использовать для дальнейшей обработки или сохранения в файл. Иногда бывает необходимо также удалить все ссылки или определенные выражения из текста. Можно использовать различные методы для обработки текста в соответствии с поставленными задачами.
Важно отметить, что каждая страница имеет свою структуру и уникальные особенности. Поэтому, при очистке текста, необходимо учитывать специфику каждой страницы и ее содержимого.
Чистка текста является важным этапом парсинга и позволяет получить чистую и структурированную информацию для дальнейшей обработки. Таким образом, чистый текст после парсинга будет иметь минимум лишних символов и будет легче обработать или преобразовать в нужный формат.
Собираем функцию

Для начала, вам необходимо знать, что каждый сайт имеет свою уникальную структуру, и чтобы успешно собрать все адреса страниц, вам нужно настроить парсер с учетом особенностей конкретного сайта.
Процесс сбора адресов страниц начинается с поиска ссылок, на которых находится нужная вам информация. Для этого вам потребуется указать настройки парсера, чтобы он знал, какие именно ссылки искать.
Когда парсер работает, он извлекает сырой текст со страницы. Затем этот текст проходит через процесс очистки, чтобы удалить ненужные символы и форматирование. После этого мы собираем функцию, которая будет обрабатывать этот очищенный текст.
Важным шагом является получение адресов всех страниц, которые мы хотим собрать. Для этого мы используем различные методы, такие как анализ ссылок на странице, поиск ссылок по ключевым словам или другие способы в зависимости от требований проекта.
Затем мы сохраняем собранный текст в файл, чтобы иметь возможность легко получить доступ к нему и использовать в дальнейшем. Конечно, настройки парсера могут быть изменены в любой момент, и вы можете настроить парсер так, чтобы он выполнял нужные вам действия с данными.
Именно собранный парсером текст может быть использован для различных целей, например, для анализа данных, создания отчетов, анализа рынка или других бизнес-процессов. Результаты парсинга могут открыть новые возможности и способы принятия важных решений для вашего бизнеса.
Если вы хотите узнать, как сделать свой собственный парсер, имейте в виду, что это достижимо благодаря разработкой парсеров и области парсинга сайтов в целом. Вы можете использовать языки программирования, такие как Python, и подключить необходимые библиотеки, такие как BeautifulSoup или Requests, чтобы начать разработку своего парсера.
Прежде чем приступить к написанию кода, убедитесь, что вы понимаете структуру сайта и знаете, какие именно данные вы хотите извлечь. Также рекомендуется изучить базовые принципы парсинга, такие как использование XPath или CSS селекторов для поиска элементов на странице.
Настройка парсера может включать в себя задание параметров запроса, настройку обработки HTML-данных и получение нужной информации из ответа сервера. Учтите, что в процессе разработки парсера могут возникать различные споры и трудности, и вам может потребоваться дополнительная помощь или консультация от экспертов в этой области.
Но не отчаивайтесь! С помощью инструкций, видеоуроков и других ресурсов вы сможете разобраться с разработкой парсеров и достичь успеха в сборе данных со сайтов.
Получаем адреса всех страниц
В этом разделе рассказывается о том, как важно иметь доступ ко всем страницам сайта, чтобы обеспечить полноценный и эффективный парсинг. Получение адресов всех страниц является неотъемлемой частью разработки парсера и позволяет получить полную картину о содержимом веб-ресурса.
Когда мы разрабатываем парсер, то одной из задач, которую нужно решить, является получение адресов всех страниц сайта. Это необходимо для того, чтобы иметь полноценное представление о структуре ресурса и обработать все необходимые данные. Каждая страница содержит уникальную информацию, которая может быть полезна для заказчика.
Получение адресов всех страниц является достижением, которое позволяет парсеру эффективно осуществлять поиск необходимых данных на веб-ресурсах. Кроме того, это позволяет предоставить заказчику более полную информацию о содержимом сайта.
Когда парсер получает адреса всех страниц, он может использовать их для извлечения данных о товарах, услугах или любой другой информации, которая нужна заказчику. Полученные адреса становятся важными элементами работы парсера, так как они позволяют запрашивать необходимую информацию и использовать ее в качестве результата работы.
Извлечение адресов всех страниц может потребовать некоторых усилий и использования специализированных инструментов, таких как Beautiful Soup или HTML-парсеры. При работе с парсером важно уметь правильно обращаться к элементам сайта, чтобы получить нужные адреса.
Для этого часто используется выражение вроде «delete_div(inner_soup(code))», которое позволяет извлечь адреса страниц из определенной рубрики или файла. Полезно также уметь работать с js-файлами, так как они могут содержать ценную информацию о структуре сайта и его страницах.
Полученные адреса всех страниц могут быть записаны в отдельный файл или редактированы с помощью специализированного редактора, чтобы получить наиболее удобное представление. Извлеченные адреса могут быть использованы в дальнейшем для получения дополнительных данных или выполнения других запросов на сайте.
Таким образом, получение адресов всех страниц является важной частью разработки парсера и позволяет обеспечить полноценный и эффективный парсинг веб-ресурсов. Эта процедура позволяет получить все необходимые данные для выполнения задачи и удовлетворить потребности заказчика в информации о сайте.
Сохраняем текст в файл
На данном этапе наш парсер обеспечивает сохранение извлеченного текста в файловом формате для дальнейшего использования. Это позволяет сохранить полученные данные в удобном виде и проводить дальнейшую обработку информации.
Для этого мы используем js-файл, который содержит необходимые функции по обработке и сохранению текста. С помощью данной функции парсер принимает текст, который мы извлекли с помощью предыдущих шагов.
В договорах-офертах и на карточках товаров важно обеспечить полное раскрытие информации о товаре, его характеристиках и условиях покупки. Наш парсер позволит вам с легкостью извлекать и сохранять эту информацию для анализа и дальнейшего использования.
Парсер также позволяет сохранять информацию о коде оператора и выражении согласия с действующими условиями договора-оферты. Таким образом, вы сможете контролировать и записывать все необходимые сведения при работе с сайтом-источником.
После извлечения и обработки информации парсер перейдет к сохранению текста в файле. В этот файл будут записаны все необходимые данные, полученные с сайта-источника. Такой подход позволит сохранить информацию в удобном для дальнейшей обработки формате.
У нас есть возможность сделать жизнь легче: наш парсер обеспечивает автоматическое определение базовой ссылки (baselink) для каждой новой страницы, на которую переходит парсер. Благодаря этому мы можем автоматически получать необходимые данные с каждой найденной страницы.
Функция по сохранению текста в файле принимает также информацию о последней обработанной странице (info). Благодаря этому вам будет легче контролировать весь процесс парсинга и быть в курсе того, на каком этапе находится обработка.
Помимо сохранения полученного текста в файл, наш парсер предоставляет возможность записи промежуточных сообщений (messages) с информацией о будущих действиях и этапах обработки. Такая функциональность позволяет упростить процесс парсинга и делает его более понятным и наглядным.
Парсер также обеспечивает процесс записи текстовой информации на каждой странице, на которой он работает. Таким образом, вы сможете в любой момент получить сведения о том, какие операции были выполнены и какая информация была получена на каждом этапе обработки.
Перейдем к настройке парсера для сохранения текста в файл. Для этого необходимо указать формат файла, в котором будут сохраняться данные. Такой подход позволяет вам выбрать наиболее удобный и предпочтительный формат файла для вас.
При использовании парсера вы сможете получить подробный отчет о процессе парсинга и сохранении текста. Это позволит контролировать каждый шаг и быть уверенным в точности и качестве получаемых результатов.
| Примеры: | С помощью нашего парсера вы сможете сделать трансграничную работу максимально эффективной и удобной. Парсер работает на всех сайтах и обеспечивает обработку информации в соответствии с заданными условиями. |
|---|---|
| Примеры: | Наш парсер позволяет обрабатывать информацию, которая находится на территории другого государства. Благодаря своей гибкости и возможностям адаптации к разным сайтам, наш парсер позволит вам работать на разных языках и получать необходимую информацию для вашего бизнеса или личных задач. |
| Примеры: | Все функции нашего парсера работают в полном соответствии с законодательством и соглашением с каждым сайтом-источником. Таким образом, вы можете быть уверены в правильности и легальности проводимых действий. |
Что дальше
После того как вы научились базовым навыкам парсинга сайтов, открывается перед вами множество возможностей. Вы станете исполнителем, который имеет доступ к бесконечному количеству материалов и данным.
Запуская парсер, вы можете передавать определенные задачи, получать нужную информацию и извлекать ее автоматически. Теперь вам не нужно заниматься этим вручную — парсер сделает это за вас, а вы сможете сосредоточиться на более важных задачах.
Теперь вы сможете получать необходимую информацию прямо на вашем компьютере — анализировать, обрабатывать, агрегировать и использовать данные для своих целей. Вам больше не нужно искать нужные материалы в интернете или ждать их от редакторов — вы можете получать их сразу же после их появления.
Кроме того, при помощи парсера вы можете извлекать данные из различных форматов — HTML, JS, XML и других. Вы можете осуществлять поиск и фильтрацию данных по ключевым словам, дате, количеству и другим параметрам.
Используя парсер, вы сможете получать информацию с любого сайта, который предоставляет доступ к своим данным. Вы сможете получать содержимое статей, получать адреса, работать с полями и шаблонами, обрабатывать html-данные и многое другое.
Парсеры позволяют работать с большим количеством данных, фильтровать их, делать запросы и получать итоговую информацию в удобной для вас форме. Вы сможете анализировать данные, автоматически обновлять информацию и использовать ее в своих проектах.
Итак, развивайтесь дальше, углубляйтесь в мир парсинга, изучайте новые возможности и приобретайте опыт. Парсеры станут вашим незаменимым помощником в работе с данными и различными материалами.
Для того чтобы узнать больше о парсинге сайтов и получить практические навыки, рекомендуем посмотреть видео-инструкции, ознакомиться со статьями Евгения Колесникова и применить полученные знания в своей работе.
Почему стоит научиться «парсить» сайты или как написать свой первый парсер на Python
Вот где входит в игру парсинг веб-сайтов. Парсинг, или извлечение данных, позволяет автоматически собирать информацию с веб-сайтов и использовать ее для различных целей. Например, вы можете создать парсер, который будет собирать информацию о товарах и ценах с различных интернет-магазинов для анализа конкурентной среды или для создания собственных агрегаторов товаров.
Когда вы пишете свой собственный парсер на Python, у вас есть полный контроль над процессом и можете настроить его по своему усмотрению. Вы можете определить, какие данные вам нужны, на каких страницах сайта искать эти данные и как обрабатывать эти данные для использования в своих проектах. Вы также можете использовать свой парсер для сбора персональных данных, при условии, что вы соблюдаете все требования и законы в отношении использования персональных данных.
Основными шагами при написании парсера на Python являются:
- Анализ структуры сайта и определение нужных страниц и ссылок
- Написание кода, который будет переходить по страницам и извлекать нужные данные
- Обработка и сохранение извлеченных данных в нужный вам формат
Один из самых распространенных подходов к парсингу веб-сайтов — использование XPath, языка запросов для извлечения конкретных элементов из HTML-документов. XPath позволяет выбрать элементы на основе их позиции в документе, их атрибутов и их отношений с другими элементами.
С помощью парсера Python и XPath вы можете извлечь данные с любого сайта, независимо от его структуры и оформления. Вы также можете использовать регулярные выражения для дополнительной обработки текстовых данных. Написание своего собственного парсера дает вам гибкость и контроль, чтобы получить данные, которые вам нужны, в формате и порядке, который вам нужен.
И так рассмотрим первый этап парсинга – Поиск данных
Нашей главной целью является достижение наиболее точного и полного предоставления информации, которую мы хотим получить с сайта. Для этого мы пишем парсер, который будет выполнять определенные запросы к сайту и обрабатывать полученные данные.
Поиск данных может быть осуществлен в различных случаях — мы можем искать информацию о конкретном товаре, описания категорий, дату публикации материалов, или другие бизнес-процессы, которые важны для нас или для наших заказчиков.
Наиболее важным аспектом в поиске данных является понимание структуры сайта-источника и определение оптимального пути для получения нужной информации. Мы должны знать, где находятся элементы, которые нас интересуют, и как обратиться к ним. Переходя по разным страницам, исполняя действия на сайте, мы можем получать больше данных и выполнять более сложную обработку, чтобы получить нужную информацию.
Парсеры, написанные нашей командой, имеют возможность настраиваться для разных сайтов и сценариев использования. Благодаря нашим специфическим настройкам и возможности использования пользовательских правил парсинга, наши клиенты получают именно те данные, которые им нужны.
Настройка парсера включает в себя указание требуемых элементов для извлечения конкретного товара или информации из категорий. Мы можем извлечь значения из различных полей, используя специфические методы и инструменты, такие как XPath. Также, настраивая пагинацию и определяя параметры запросов, мы можем получать данные со страниц разных типов и диапазонов.
При использовании наших услуг, вы можете быть уверены в полном соблюдении прав и конфиденциальности данных. Мы строго соблюдаем политику использования cookie и защищаем все полученные данные согласно договора-оферты.
Также, для удобства использования, наше программное обеспечение предоставляет возможность сохранения данных в различных типах файлов, включая наиболее распространенные форматы, такие как CSV или Excel. Это позволяет нашим клиентам анализировать и использовать полученные данные в своих бизнес-процессах без дополнительных усилий.
Итак, наш первый этап парсинга — это поиск данных на сайтах. У нас есть все необходимые инструменты и опыт, чтобы помочь вам получить нужную информацию из веб-ресурсов. Свяжитесь с нами сегодня и узнайте, как мы можем помочь вам улучшить ваш бизнес с помощью парсеров сайтов и получения данных!
Второй этап парсинга – Извлечение информации
Извлечение информации осуществляется с помощью использования различных тегов и выражений. Как правило, для извлечения конкретных данных необходимо знать структуру сайта, его теги и особенности.
Для эффективного извлечения информации можно использовать шаблоны и настройки парсера. С их помощью можно указать нужные теги и параметры для извлечения данных. Это позволяет значительно упростить процесс парсинга и обработку текста.
Однако, в некоторых случаях извлечение информации может требовать вмешательства вручную, особенно при необходимости обработки удаленных или сложных данных. В таких ситуациях опытные парсеры могут использовать специальные функции и запросы для получения нужной информации.
На этом этапе также стоит обратить внимание на обработку большого количества информации и запросов. Некорректное использование парсера может привести к медленной работе или ошибкам в получении данных. Поэтому важно оптимизировать парсеры и учитывать их возможности и ограничения.
Итак, на втором этапе парсинга – Извлечение информации, используя различные методы и настройки, вы сможете получать необходимые данные с веб-сайтов. От навигации по тегам и выражениям до настройки запросов и обработки больших объемов информации, эта часть работы является ключевой для успешного парсинга и получения актуальных данных.
Комірник
В этом разделе рекламного поста мы расскажем о важном этапе парсинга сайтов, который поможет вам получить необходимые данные для вашего бизнеса. Остановимся на пункте №15, где речь идет о сохранении данных.
На этом этапе парсера вы можете сохранить полученные данные в файле формата HTML. Это очень удобно, так как файл в формате HTML позволяет сохранить структуру и содержимое страницы, что будет полезно при дальнейшей обработке информации.
Важно отметить, что на этом этапе вы можете настроить парсер таким образом, чтобы он сохранял не только текст, но и другие данные, такие как адреса страниц, номера договоров-оферт, категории товаров и многое другое. Для этого вам понадобится использовать операторы и функции языка программирования, например, beautifulsoup и html_code.
Определение тегов, которые нужно сохранить, также является важной частью этого этапа. Вы можете указать нужные теги в коде парсера, чтобы он определенным образом обрабатывал запрошенные данные. Это позволит получить только нужные поля и исключить все ненужное содержимое.
Запуск парсера на этом этапе может потребовать нажатия кнопки или выполнения специализированного запроса. Это можно настроить в коде парсера, чтобы он автоматически выполнял необходимые действия.
Подключив этот этап парсинга к вашему проекту, вы получите возможность добраться глубже в содержимое сайтов, получить все необходимые данные для анализа и использовать их в дальнейшей обработке.
Таким образом, этап сохранения данных является важным и неотъемлемым этапом жизни любого парсера. Он позволяет получить необходимые данные с веб-сайтов, а также обрабатывать их в соответствии с требованиями заказчика. Если вам понадобится сохранить данные с сайта, настроить парсер на извлечение конкретных полей или адресов, то обязательно прочитайте этот раздел и ознакомьтесь с последними техниками и способами парсинга.
И последний этап парсинга – Сохранение данных
На этом этапе мы остановимся на процессе сохранения полученной информации, которая позволяет нам получать не только сырой текст с сайта-источника, но и полезные данные для дальнейшего использования.
Для того чтобы сохранить данные, которые нам необходимы, мы подключим функцию сохранения, которая позволит нам сохранить результаты парсинга в нужном нам формате.
Подключение функции сохранения позволит нам использовать полученные сведения в различных целях – от анализа информации до создания отчетов или определения трендов в определенной области.
Для этого мы будем записывать нужные нам данные в определенный файл, используя соответствующие настройки. Это позволит нам сохранить информацию о товарах, субъектах или услугах в удобном для нас формате.
При сохранении данных мы можем настроить режим удаления лишних элементов страницы, чтобы получить только нужную информацию. Также можно использовать операторы и теги для работы с полученными данными. Важно учесть, что функция сохранения данных должна быть настроена согласно нашим потребностям.
При сохранении данных мы также можем определить параметры сбора информации, такие как номер страницы, последней результата или другие настройки. Это позволит нам получать актуальные данные и организовать процесс парсинга максимально удобным для нас образом.
Наша услуга парсинга сайтов предоставляет широкие возможности для сбора информации с различных сайтов. Заключив соглашение о сотрудничестве с нашей компанией, вы можете быть уверены в качественной и точной обработке данных и получении необходимой информации для своего бизнеса или научных исследований.
Если вам нужны дополнительные сведения о наших услугах или настройках парсера, читайте информацию в нашей рубрике FAQ или свяжитесь с нами для получения подробной информации.
Как сделать парсер сайта самостоятельно текстовая инструкция +видео
В этом разделе мы расскажем, как самостоятельно создать парсер сайта. С помощью нашей текстовой инструкции и видеоматериалов вы сможете овладеть необходимыми навыками и инструментами для выполнения данной задачи.
Первым этапом является определение структуры сайта. После анализа страницы блоками и тегами, вы сможете выделить нужные элементы для парсинга, такие как заголовки, описания, текстовые блоки и т.д.
Следующим шагом будет написание кода парсера. С помощью языка программирования Python и библиотеки для парсинга веб-страниц, вы сможете создать свой собственный парсер. Видео-инструкции помогут вам лучше разобраться в процессе создания парсера.
После того, как парсер будет готов, вы сможете запускать его для получения необходимой информации с сайтов. Парсер может извлекать данные из различных мест страницы, таких как заголовки, описания, ссылки, даты и многое другое.
Используя предоставленные инструкции, вы сможете настроить парсер под свои цели. Вы можете получать информацию о товарах, услугах, статьях, материалах СМИ и других информационных ресурсах.
Определенные параметры запроса, такие как базовая ссылка (baselink), позволят парсеру получать информацию только с определенного сайта или раздела. Также вы можете использовать уникальные идентификаторы каждого элемента страницы, чтобы получать только нужные данные.
Парсер может быть настроен на работу с пагинациями, что позволит получать данные с нескольких страниц. Вы можете определить последнюю страницу пагинации и получать информацию со всех страниц данного раздела.
Итоговая инструкция также даст вам информацию о том, как получать данные из действующего периода, как работать с cookie файлами и как сохранять полученные данные в нужный вам формат файлов.
В результате, вы сможете разработать свой собственный парсер сайтов, который сможет автоматически получать необходимую информацию с веб-ресурсов. Это может быть полезно для аналитики, бизнес-процессов, исследований рынка и многих других областей деятельности.
Видео-инструкция по созданию парсера
В этом разделе рекламного поста мы предлагаем вам ознакомиться с видео-инструкцией по созданию парсера. Видео содержит полезные советы, которые помогут вам освоить основные принципы разработки парсера сайтов.
Во время разработки парсера вы узнаете о последней технологии парсинга, а также о применении операторов для сбора информации с сайтов. Кроме того, вы узнаете о порядке настройки парсера для себя и о возможности записи результатов с помощью клика в блоке пагинаций.
Операторы в парсинге сайтов имеют большое значение и используются для обработки разных случаев использования. При разработке парсера мы обеспечим доступ к коду страницы, который включит в себя права и согласия, когда это необходимо, кроме того, мы определим вид страницы и информационных блоков, в которых нужны настройки парсера.
Для создания парсера необходимо сделать настройки в файле, который будет задавать параметры запроса. В этом файле можно определить дату, порядок запросов и сроки выполнения задач. При разработке парсера учтите возможность работы с потомками и порядком их обработки. Этот файл является неотъемлемой частью бизнес-процессов вашего сайта.
Важным этапом создания парсера является настройка извлечения полей для конкретного продукта. Для этого в настройках парсера используется оператор baselink, который указывает на следующую ссылку или даже на раздел каталога. Настройка извлечения полей включает в себя информацию о разных атрибутах и параметрах запроса.
При создании парсера важно также учитывать настройку извлечения ссылок на карточки товаров из категории. Для этого используются операторы и селекторы, которые позволяют парсить страницу с множеством ссылок и извлекать только нужные.
Для обработки страниц с пагинацией, в парсере можно настроить пагинации на английском языке pagination. В этом случае парсер будет автоматически обрабатывать постраничную навигацию и собирать данные со всех страниц.
Основной задачей парсера является сбор данных с сайтов и сохранение их в определенный тип файла. В этом разделе вы узнаете, как настроить выгрузку данных и какие форматы файлов могут быть использованы для сохранения результатов парсинга.
В первом этапе разработки парсера рекомендуется ознакомиться с кратким уроком по использованию Xpath для парсинга сайтов с примерами. В этом уроке вы найдете информацию о структуре сайта, о выборе тегов и о разных случаях использования предикатов.
Также мы рекомендуем ознакомиться с примером HTML файла, который поможет вам лучше понять, как выбрать конкретные теги с помощью XPath. В этом примере вы узнаете о разных способах выбора тегов, включая выбор неизвестных заранее тегов и выбор нескольких путей.
Заказать разработку парсеров можно у нас, экспертов в данной области. Мы предлагаем индивидуальные решения для различных задач и оказываем поддержку после выполнения заказа.
Если вы хотите научиться парсить сайты и материалы СМИ с помощью JavaScript и Nodejs, то мы советуем ознакомиться с видео-уроком от специалиста Евгения Колесникова. В этом уроке вы узнаете, как устроен парсинг сайтов на основе этих технологий и как установить необходимое программное обеспечение для этого.
Парсинг сайтов с использованием JavaScript и Nodejs позволяет эффективно обрабатывать различные типы пагинации, включая отдельные страницы и бесконечную подгрузку по клику.
Мы надеемся, что данная видео-инструкция поможет вам освоить основные принципы парсинга и создания собственного парсера. Ничто не вечно, и сегодня вы можете начать свой путь к успешному парсингу сайтов.
Еще раз напоминаем, что результаты парсинга сайтов могут быть использованы только с согласия владельцев сайтов. Пожалуйста, учитывайте права и законы, когда используете данные полученные в результате парсинга.
Если у вас возникли вопросы или вам нужна дополнительная информация, обратитесь к нам. Мы с радостью поможем вам.
Создадите настройку для нового парсера
В данном разделе будет рассмотрена процедура создания настройки для нового парсера, который позволяет собирать информацию с сайтов-источников. Для успешного извлечения необходимых данных необходимо учитывать множество факторов и использовать специальные инструменты и методы парсинга.
Основной элемент, определяющий успешность парсинга, является набор тегов, которые соответствуют искомым данным на сайте-источнике. Настройки парсера включают в себя выбор этих тегов и определение правил для извлечения информации из них. Важно также учесть особенности сайта-источника и работать с тегами соответствующим образом.
Подключение настройки для нового парсера осуществляется путем указания URL страницы сайта-источника, с которой необходимо собрать информацию. Для этого в настройках парсера используйте операторы и методы, позволяющие определить требуемую страницу.
Один из способов настройки извлечения информации заключается в использовании оператора «urlSearchParams». С его помощью можно задать условия, по которым будет определена страница для парсинга. В результате парсера будет произведено извлечение информации только на страницах, соответствующих указанным условиям.
В процессе создания настройки для парсера необходимо также определить структуру страницы, на которой будет осуществляться парсинг. Для этого используйте методы и операторы, позволяющие получить доступ к нужным элементам страницы и извлечь необходимую информацию.
Когда настройка для нового парсера будет готова, можно приступить к выполнению парсинга. Используйте указанное в настройке имя исполнителя, чтобы проверить настройку на своем сайте-источнике. По завершении парсинга будет получен массив ссылок на карточки товаров или другую информацию, указанную в настройке.
Важно также отметить, что процесс настройки парсера может включать и другие действия и инструменты, которые необходимо использовать в зависимости от конкретных требований и особенностей сайта-источника.
На следующем шаге введите ссылку на карточку товара и на категорию
На данном шаге вы должны ввести ссылку на конкретную карточку товара, а также указать категорию, к которой этот товар относится. Это необходимо для того, чтобы парсер мог извлечь информацию, соответствующую вашим условиям.
При разработке парсера важно учесть, что каждый сайт имеет свою уникальную структуру, которую нужно анализировать и настраивать для извлечения нужной информации. Конкретные операторы и методы, которыми вы будете пользоваться, зависят от выбранного сайта-источника.
При предоставлении ссылки на карточку товара и указании категории, вы даете парсеру информацию о том, где находится нужная информация на сайте. Например, вам может понадобиться извлечь информацию о цене товара, его характеристиках и других деталях. Или же вы можете заинтересованы в сборе определенного количества ссылок на товары для последующей обработки.
Вручную указывая ссылку на карточку товара и категорию, вы помогаете парсеру определить точную структуру сайта и необходимые методы обработки данных. Это позволяет точно извлекать нужную информацию на страницах сайта.
Парсер может быть настроен таким образом, чтобы перед началом парсинга выполнялся определенный набор операций. Например, это может быть ожидание загрузки страницы, авторизация на сайте или прокрутка до конкретного элемента на странице. Все это определяется вами при настройке парсера.
Важно отметить, что при парсинге информационных ресурсов необходимо учитывать условия использования сайта, с которыми вы должны быть согласны. Некоторые сайты могут ограничивать количество запросов парсера или требовать закрепления вашего IP-адреса за определенной территорией. Эти условия определяются оператором сайта и должны быть соблюдены.
После указания ссылки на карточку товара и категорию, выражение, которое определяет необходимые элементы на странице для извлечения нужной информации, передается парсеру для обработки. Затем парсер начинает сбор данных, соответствующих вашим условиям.
В процессе парсинга могут возникнуть ситуации, когда необходимо извлечь данные из неизвестных заранее тегов или выбрать несколько путей для получения информации. В таких случаях вы можете использовать предикаты и различные методы выбора и обработки данных, чтобы получить нужный результат.
При запуске парсера важно убедиться, что все настройки выполнены корректно и сбор данных происходит в соответствии с ожидаемыми результатами. Путем проверки и анализа данных вы можете убедиться в правильности работы парсера и внесении необходимых корректировок при необходимости.
Как только парсер успешно выполнит свою работу, вы получите данные в заданном формате, который можно сохранить в виде файлов для дальнейшего анализа или использования в других проектах. Таким образом, парсер предоставляет вам удобный инструмент для автоматизации сбора данных с веб-сайтов и получения уведомлений о новых обновлениях или изменениях.
| messagesNote: | при настройке парсера обратитесь к документации оператора сайта для получения подробной информации о доступных методах и правилах использования парсера. |
Настройка парсера
В данном разделе рассмотрим процесс настройки парсера для получения нужных данных с сайта. Подключение и использование парсера позволит считывать информацию с HTML-документа сайта-источника и извлекать необходимые блоки данных.
Для начала работы с парсером, необходимо определить несколько задач и настроек. Вставка подключения в код страницы сайта источника является первым шагом. В этой подготовительной работе также можно определить нужные категории или рубрики, которые будут парситься.
Одной из основных задач является определение элемента HTML-документа, соответствующего нужным данным. В этом помогает использование XPath, CSS-селекторов или других подходящих методов. Пример кода, который позволяет определить нужный элемент, может выглядеть следующим образом:
beautifulsouphtml_code.select('html-код элемента')
Далее, после определения нужного элемента, необходимо произвести извлечение данных из этого элемента. Для этого используется соответствующий код, который будет указывать на то, какие данные и в каком формате должны быть извлечены.
Важным моментом является обработка полученной информации. Можно удалить ненужные элементы или произвести другую обработку данных в соответствии с конкретными требованиями проекта. Пример кода для удаления определенного элемента может выглядеть следующим образом:
delete_divinner_soupcode.extract()
После обработки данных, необходимо сделать запись полученных результатов в соответствующий файл. Это можно осуществить с помощью следующего кода:
fs.appendFileSync('путь до файла', 'articles.html')
Таким образом, в разделе настройки парсера мы определяем все нужные параметры, настраиваем процесс извлечения данных с сайта и проводим обработку полученной информации, чтобы в итоге получить необходимые html-данные.
Настройка извлечения полей для конкретного продукта
Прежде всего, необходимо подключиться к HTML-коду страницы, с которой мы будем работать. На этом этапе мы задаем задачу парсеру извлечь определенные данные из указанной страницы.
Когда мы переходим к конкретной странице или разделу сайта, мы можем рассмотреть структуру HTML-кода и определить, какие элементы и теги нам нужно извлечь и обработать. Для этого мы обращаемся к рубрику или категорию, где находится нужный нам товар или услуга.
Одним из способов извлечения данных из элементов HTML-кода является использование инструментов, таких как BeautifulSoup или других библиотек для обработки HTML и XML. Мы можем использовать эти инструменты для поиска и извлечения нужной информации на странице. Например, мы можем использовать beautifulsoup.html_code для извлечения данных из определенного элемента.
Когда мы уже определили необходимые элементы на странице, мы можем приступить к настройке парсера для извлечения этих данных. Для этого мы можем использовать различные операторы и методы для работы с данными. Например, мы можем использовать операторы, такие как «find» или «find_all» для поиска определенных элементов на странице.
После того, как данные успешно извлечены и обработаны, мы можем сохранить их в нужный нам формат файлов, такой как CSV, JSON, или другой.
Таким образом, настройка извлечения полей для конкретного продукта является важным шагом в разработке парсера. Она позволяет нам получать необходимую информацию о товаре или услуге с помощью парсинга HTML-кода и обработки данных. Сделав все настройки и установив нужные параметры, мы получим точную и полную информацию о субъекте, которую можно использовать для разного рода анализа, статистики или оценки продукта или услуги.
Как извлекать значения

В данном разделе рекламного поста мы рассмотрим способы извлечения значений из веб-страницы с помощью парсера. Это очень полезный навык, который может быть применен в различных сферах, начиная от веб-скрапинга и анализа данных, и заканчивая автоматизацией задач в сфере интернет-маркетинга.
Для извлечения значений мы будем использовать инструмент по имени Zennoposter, который позволяет с легкостью осуществлять парсинг сайтов. Он имеет интуитивно понятный интерфейс и позволяет выполнять задачи связанные с извлечением данных с сайтов без необходимости программирования на языках программирования.
Важным элементом при парсинге сайта является определение структуры сайта. Это позволяет парсеру понять, где искать нужные нам данные. Для этого мы можем использовать инструменты разработчика веб-браузера, такие как Chrome DevTools или Firefox Developer Edition.
Затем мы можем использовать Zennoposter для написания кода парсера. В этом коде мы опишем все необходимые действия: от открытия страницы и получения ссылок на карточки товаров, до извлечения значений и их сохранения.
Для извлечения значений мы используем язык запросов XPath. С его помощью мы указываем парсеру, какие элементы и атрибуты нам нужны. Например, мы можем использовать XPath выражение для выбора всех заголовков на странице или для извлечения цены товара.
При необходимости мы также можем добавить дополнительную логику обработки данных. Например, мы можем использовать JavaScript для выполнения сложных операций над значениями, полученными с сайта-источника.
Завершая настройку парсера, мы указываем файл, в который будут сохранены извлеченные данные. Мы можем выбрать разные форматы файлов, включая текстовые файлы, таблицы Excel или базы данных.
Процесс парсинга сайта может быть автоматизирован настолько, что можно задать переходы по страницам с помощью клика или обработки других пользовательских событий. Также, мы можем оперировать с различными рубриками и потомками, что позволяет точно указать, какие данные мы хотим получить.
Итоговое выражение, которое определяет какие данные будут получены с сайта, может быть достаточно сложным и многоуровневым. Оно включает в себя команды для определения элементов страницы, обработку данных и сбор конечного результата из различных источников.
Итак, учитывая все вышеизложенное, наш парсер настраивается для того, чтобы получать данные с веб-страницы, обрабатывать их и сохранять в удобном формате. Разработка парсеров становится более доступной с помощью инструментов и ресурсов, таких как Zennoposter и курсы Евгения Колесникова, которые помогут вам освоить этот навык и применить его в вашей работе или проекте.
Ниже представлен пример кода парсера на языке JavaScript, который используется в Zennoposter для обработки данных с выбранного сайта:
// Здесь указываем путь к HTML-файлу, который содержит данные для парсинга
const fs = require('fs');
const path = require('path');
const filePath = path.join(__dirname, 'articles.html');
// Определяем базовую ссылку для сайта-источника
const baseLink = 'https://example.com/';
// Извлекаем данные из HTML-файла
const rawHtml = fs.readFileSync(filePath, 'utf-8');
// Создаем экземпляр парсера
const soup = new JSSoup(rawHtml);
// Извлекаем значения с помощью выбора тегов через XPath
const title = soup.select('h1')[0].text;
const description = soup.select('p')[0].text;
// Получаем ссылку на страницу субъекта
const subjectLink = baseLink + soup.select('a')[0].attrs.href;
// Получаем дату публикации
const date = soup.find('span', {'class': 'date'}).text;
// Итоговая обработка и сохранение данных
const result = {
'title': title,
'description': description,
'subjectLink': subjectLink,
'date': date
};
const resultJson = JSON.stringify(result);
fs.appendFileSync('parsed_data.json', resultJson);
Выше приведен лишь один из возможных подходов и код может отличаться в зависимости от особенностей сайта, на котором производится парсинг. Важно понимать, что каждый парсер уникален и требует индивидуальной настройки в соответствии с требованиями и целями проекта.
Запустив парсер, мы получаем данные с веб-страницы, производим их обработку и сохраняем в указанный файл. Благодаря развитию технологий автоматизации и парсинга, процесс извлечения значений становится проще и доступнее для широкого круга пользователей.
2 Настройка извлечения ссылок на карточки товаров из категории
Подключимся к сайту с помощью пользователя, которому разрешен доступ к этой функции. Мы переходим на страницу, где находится категория, для которой хотим получить ссылки на карточки товаров.
В коде парсера используем оператор beautifulsouphtml_code(), который позволяет получить HTML-код страницы сайта-источника. Теперь, имея этот код, мы можем приступить к сбору нужных нам ссылок на карточки товаров.
Для того чтобы получить ссылки, которые находятся на странице выбранной категории, мы воспользуемся оператором page_num(). При его использовании следует указать число, соответствующее странице категории, иначе парсер не сможет найти необходимую информацию и собрать ссылки.
Полученные ссылки на карточки товаров добавляем в итоговый текст или сохраняем в файл для дальнейшего использования. Таким образом, после применения данной настройки, мы получаем завершенную часть парсинга, позволяющую собрать информацию о товарах из выбранной категории.
Благодаря возможностям нашего парсера, мы можем извлекать данные из различных сайтов с трансграничной операцией и создавать структурированный порядок полученных результатов.
Приступайте к настройке и извлекайте необходимую информацию для вашего бизнеса! Успешное выполнение этого шага далеко не всегда просто, но вы можете быть уверены, что мы предоставляем достижение ваших целей.
3 Настройка пагинаций на английском pagination
При настройке пагинации на сайтах, мы перейдем к обработке механизма перехода между страницами. Вручную получать и обрабатывать каждую страницу может быть трудоемкой задачей, особенно когда речь идет о сборе информации из большого количества статей или другого контента.
Для упрощения процесса сбора данных, мы используем возможность автоматической обработки пагинаций. Записывая правила и настройки пагинации, мы можем предоставить редактору парсера информацию о том, как следует обработать страницы с различной структурой.
На следующем этапе, согласуя с редактором, мы запишем все необходимые настройки пагинаций, включая указание на добавление численных потомков в URL-ссылки страниц пагинации и добавление необходимых параметров запроса. При этом, мы учтем договоренности, установленные в рамках договора-оферты или юридического соглашения между нами, оператором парсера, и владельцем сайта, субъектом обработки html-данных.
Осуществляя настройку пагинаций на сайтах, наша цель — получить полный контент сайта, включая все категории и подкатегории, а также осуществить извлечение информации с учетом указанных правил и параметров пагинации. Подключив алгоритмы парсинга, мы сможем получить полные данные и содержимое сайтов, включая тексты, изображения, ссылки и другие элементы.
Применение пагинации значительно упрощает и ускоряет процесс парсинга, позволяя собрать нужную информацию с сайтов, посвященных различным субъектам бизнес-процессов. Запрашивая данные с определенных страниц и категорий, мы можем извлекать только необходимую информацию, кроме того, настраивая пагинацию позволяет избежать сбоев и нагрузки на сайты.
В случае использования пагинации, перед началом процесса парсинга мы уточним возможность и условия получения согласия субъекта данных на предоставление информации, которая содержится в страницах пагинации. Будут ли ссылки на страницах пагинации отображаться публично или же они предназначены только для внутреннего использования компанией или лицензиаром.
Следуя заданным правилам, мы настроим парсер так, чтобы он мог получить и обработать нужные данные с использованием пагинации, не нарушая законодательство. Наше решение поможет автоматизировать сбор данных и сохранить их в нужный тип файла для дальнейшей обработки.
Как запускать парсер
Для начала, нам нужно создать js-файл, который будет содержать код для парсинга нужной нам страницы. Настоящая страница должна быть предоставлена в формате beautifulsouphtml_code, что поможет нам легко получить доступ к элементам страницы.
По запуску парсера, необходимо правильно настроить опции и создать файл настроек со списком тегов, которые мы хотим извлечь. Это далеко не простая задача, но с помощью правильных настроек и тегов мы сможем получить всю нужную нам информацию.
Важным этапом является подключение cookie для получения доступа к закрытым страницам или предоставлению личных данных о субъектах. Опять же, настройка процесса подключения позволит нам выполнить эту задачу успешно.
Для начала работы с парсером, мы должны записать полученные данные в файл. Для этого мы используем функцию fs.appendFileSync и задаем путь к файлу, в котором будут храниться полученные данные.
В итоге, после выполнения всех этих шагов, мы получим информацию, извлеченную с веб-страницы и записанную в файл. Наш парсер успешно раскроет содержимое страницы и извлечет нужную нам информацию, включая все заданные теги, шаблоны и описания.
Запуск парсера — это процесс, который необходимо выполнять в соответствии с определенными правилами и настройками. Успешное выполнение этого процесса позволяет нам получить нужную информацию и использовать ее для наших целей.
Что такое grabCatalog формат
Итак, каким образом можно получить информацию с веб-сайтов? Для этого разработчику потребуется специальный парсер, способный вытягивать нужные данные из веб-страниц. Один из таких парсеров, работающий с grabCatalog форматом, позволяет исполнителю собирать и обрабатывать контент, находящийся на веб-страницах.
Используя grabCatalog, операторы парсинга могут получать информацию о различных аспектах онлайн-товара, таких как его характеристики, фотографии, сведения о производителе и т.д. GrabCatalog формат предоставляет возможность извлекать данные из разных категорий товаров или статей и предоставлять их в удобной для обработки форме заказчику. Это сочетание комфорта и точности при выполнении парсинга.
Процесс работы с grabCatalog форматом:
Для начала, необходимо установить необходимое программное обеспечение для работы с grabCatalog форматом. Затем, парсер с помощью js-файла отправляет запрос на страницу сайта, который содержит необходимую информацию. После этого парсер начинает сбор данных с этой страницы и извлекает их, используя специальные выражения и ссылки.
GrabCatalog формат позволяет сделать запрос на определенного субъекта, то есть найти конкретный элемент на странице, содержащий информацию, которую нужно извлечь. Это позволяет придать гибкость и точность парсингу, так как можно извлечь только нужные данные и не затрагивать остальные элементы страницы.
Использование grabCatalog формата при парсинге сайтов позволяет операторам получить сведения о товаре, находящемся на определенной странице. Для этого необходимо указать ссылку на карточку товара и категорию, которая содержит этот товар. После этого заказчик получает данные в необходимом типе файла, установленном заранее.
Важно отметить, что grabCatalog формат облегчает процесс сбора информации, включая данные, необходимые для бизнес-процессов. Он позволяет обрабатывать текстовую и другую информацию, извлекаемую со страниц сайтов, и сохранять ее для дальнейшего анализа или использования. GrabCatalog формат является эффективным инструментом для сбора, обработки и раскрытия данных со страниц сайтов, что позволяет оптимизировать бизнес-процессы на территории пользователя.
Таким образом, использование grabCatalog формата позволяет упростить и ускорить процесс сбора и обработки информации со страниц сайтов, что делает его неотъемлемой частью современных промышленных и коммерческих бизнес-процессов.
Как настроить выгрузку данных в определенный тип файла
Для начала, давайте представим себе ситуацию, когда заказчик парсинга нуждается в получении информации в определенном формате файла — например, Excel или CSV. Для этого нам понадобится использовать библиотеку BeautifulSoupHTML для работы с HTML-кодом полученных страниц.
Основной шаг, который необходимо выполнить, — это описание структуры сайта и извлечение нужных данных по заданным категориям. В результате парсинга мы будем получать сведения о текстах на страницах, ссылках и других информационных элементах, которые будут использоваться для формирования результата выгрузки.
Для получения данных в нужном формате, мы можем использовать различные методы. Например, если нам необходимо получить только текст на заданной странице, мы можем использовать оператор BeautifulSoupHTML_code или Beautifulsoup.find().text. Если же нам нужно извлечь ссылки на странице, мы можем использовать метод Beautifulsoup.find_all(‘a’), который вернет нам список всех ссылок на странице.
В некоторых случаях, для получения данных в определенном формате может потребоваться дополнительное взаимодействие с сайтом. Например, если сайт предоставляет информацию только после нажатия на определенную кнопку или выполнения запроса с использованием параметра URLSearchParams, мы можем использовать код, предоставленный разработчиком Eugeny Uzenkov в его статье «Как парсить сайты и материалы СМИ с помощью JavaScript и Nodejs». Этот код позволяет осуществить подключение к сайту и получение необходимой информации.
Последним шагом в настройке выгрузки данных является выбор типа файла выгрузки. Мы можем сохранять данные в различных форматах файлов, включая Excel, CSV или другие форматы, которые удобны для дальнейшей работы заказчика. Для этого мы можем использовать библиотеки, такие как pandas или csv, которые предоставляют удобные инструменты для сохранения данных в нужном формате.
Таким образом, настройка выгрузки данных в определенный тип файла включает в себя описание структуры сайта, извлечение необходимых данных, обработку информации и сохранение результата в нужном формате. Этот шаг позволяет существенно оптимизировать бизнес-процессы и упростить работу заказчика с полученными результатами парсинга.
Краткий Урок-введение в Xpath для парсинга сайтов с примерами
Xpath незаменим при парсинге, так как позволяет точно указать путь к нужным данным на странице. Например, с помощью Xpath можно выбирать определенные теги, атрибуты, значения элементов и многое другое.
Для начала, давайте рассмотрим простой пример использования Xpath для получения адресов всех страниц на сайте. Представим, что у нас есть HTML-документ, содержащий ссылки на различные страницы.
Наша задача — получить все адреса страниц и сохранить их в файл или вывести на экран. Для этого мы воспользуемся функцией Xpath, которая позволяет выбирать все элементы, соответствующие определенному шаблону.
Для начала, откроем файл с html-данными с помощью любого текстового редактора или скопируем html-код из браузера. Затем, подключим необходимые библиотеки и выполним парсинг страницы с помощью функции Xpath.
Наш код будет выглядеть примерно следующим образом:
import requests
from lxml import html
def parse_page(url):
response = requests.get(url)
html_code = response.content
tree = html.fromstring(html_code)
addresses = tree.xpath("//a/@href")
return addresses
url = "http://example.com"
addresses = parse_page(url)
for address in addresses:
print(address)
Обратите внимание, что в данном примере мы используем библиотеку requests для получения доступа к указанной странице, а также библиотеку lxml для работы с Xpath. Вместо «http://example.com» может быть указан любой другой адрес страницы.
Когда мы запустим данный код, он выполнит запрос к указанной странице, получит html-данные, выполнит парсинг с помощью Xpath, и выведет наиболее интересующую нас информацию — ссылки на другие страницы.
Таким образом, понимание и использование Xpath открывает перед нами множество возможностей для успешного парсинга веб-страниц. Независимо от того, собираете ли вы информацию для личных целей или предоставления услуг, парсинг с помощью Xpath является эффективным и мощным инструментом в вашем арсенале.
И помните, что важно использовать парсинг сайтов и материалов СМИ с соблюдением правовых и этических норм. Это значит, что вы должны быть осведомлены об ограничениях права на доступ к информации и использование данных, которые имеете в своем распоряжении.
Пример HTML файла
HTML файл содержит структуру страницы, которая определяет взаимное расположение элементов на сайте. Для успешного парсинга необходимо правильно настроить параметры и настроить парсер таким образом, чтобы он мог получать необходимую информацию с каждой страницы сайта.
В нашем примере HTML файла, файл будет содержать информацию о каждом запросе, полученном в момент обработки кода парсером. Каждая страничка будет соответствовать определенному запросу и будет содержать следующую информацию:
| Поле | Описание |
|---|---|
| Ссылка | Ссылка на страницу с информацией о запросе |
| Описание | Описание запроса |
| Закреп | Информация о закрепленном запросе |
| Субъект | Субъект запроса |
| Заказчик | Информация о заказчике запроса |
| Исполнитель | Информация об исполнителе запроса |
| Информация | Информация о каждом запросе |
После получения HTML файла, оператору парсера необходимо будет настроить парсер таким образом, чтобы он мог получать информацию по указанным ссылкам и извлекать нужные данные. Для этого будут использоваться различные настройки и инструменты.
Полученный результат сохраняется в файле с расширением «.info» в виде таблицы, чтобы пользователь мог удобно просмотреть полученную информацию. При необходимости, данную информацию можно представить в виде пользовательского отчета или перенести в другой формат для дальнейшей обработки.
Выбор тегов для извлечения конкретных данных с использованием XPath
В этом разделе рекламного поста мы рассмотрим, как можно выбрать нужные теги для извлечения конкретных данных с помощью XPath. Это особенно полезно, когда у нас есть большое количество различных данных на веб-странице, и мы хотим извлечь только определенные сведения.
XPath предоставляет нам мощные возможности для выделения нужных элементов на странице. С его помощью мы можем выделить теги по различным критериям, таким как их класс, идентификатор, атрибуты и их иерархическую структуру.
Для начала, перед тем как перейти к самой обработке, нужно определиться с тегами, которые нам требуется извлечь. Мы можем использовать такие конструкции, как селекторы элементов, предикаты и указание пути к нужным значениям.
Приведем пример с использованием XPath для выделения нужных данных на странице. Предположим, что у нас есть веб-страница с каталогом товаров, где каждая карточка товара содержит информацию о его названии, цене и описании.
Для извлечения названия товара мы можем использовать XPath выражение следующего вида:
//div[@class='product-title']/h3
А для извлечения цены и описания товара, мы можем использовать соответствующие XPath выражения:
//div[@class='product-price']/span
//div[@class='product-description']
Примерно таким образом мы выбираем конкретные теги, содержащие нужную нам информацию. Запишем эти выражения в виде кода и передадим разработчику, который будет выполнять эту задачу. Ему будет достаточно по этому коду понять, как именно нужно производить выборку данных.
Таким образом, при предоставлении заказчику XPath выражений для выбора нужных тегов, мы упрощаем ему задачу по обработке данных и позволяем сосредоточиться на более важных бизнес-процессах.
В итоге, при использовании XPath и правильном выборе тегов, мы сможем получить доступ к нужным данным на странице, выполнить их обработку и использовать в своих дальнейших операциях и услугах. Это позволяет нам автоматизировать процессы сбора и анализа информации и существенно ускорить выполнение повторяющихся задач.
Примечание: Для выполнения обработки данных, можно использовать различные библиотеки, такие как BeautifulSoup или универсальную библиотеку для парсинга страниц — Selenium. Их использование позволяет производить выборку данных не только посредством XPath, но и по другим методам обработки HTML и XML.
Таким образом, у нас есть возможность выбирать нужные теги и элементы на странице с помощью XPath, что позволяет нам извлекать конкретные данные, обрабатывать их и использовать в своей работе для различных целей.
Заказать разработку парсеров вы можете у нас. Мы предоставляем услуги по созданию профессиональных парсеров, которые могут помочь вам в сборе и обработке данных с различных веб-сайтов и материалов СМИ. Не стесняйтесь обращаться к нам для получения подробной информации и консультаций. Наши специалисты всегда готовы помочь вам в автоматизации ваших бизнес-процессов и улучшении эффективности вашей работы.
Предикаты
Когда мы парсим сайт, нам часто нужно найти определенные элементы, содержащие необходимую информацию. Для этого мы используем различные предикаты, которые позволяют указывать условия для поиска элементов.
Например, представим, что у нас есть страница товаров, на которой отображается список товаров с их названиями, ценами и ссылками. И нам нужно извлечь только те товары, цена которых меньше определенной суммы.
Для этого мы можем использовать предикаты. Например, мы можем задать следующее условие: «найти все элементы с классом ‘product’, у которых цена меньше 100 рублей». Такой предикат может выглядеть следующим образом:
soup.find_all('div', class_='product', attrs={'data-price': lambda x: int(x) < 100})
В данном примере мы используем функцию lambda для задания условия. Эта функция принимает значение атрибута 'data-price' каждого элемента и сравнивает его с 100. Если цена меньше 100, элемент будет добавлен в результат.
Использование предикатов позволяет гибко настраивать процесс парсинга, выбирая только нужные данные. Благодаря этому, мы можем извлечь только те товары, которые соответствуют нашим конкретным требованиям.
Это лишь один из примеров использования предикатов. В зависимости от целей парсинга и структуры сайта, мы можем создавать различные предикаты для извлечения нужных данных.
Использование предикатов и других техник парсинга поможет вам получить итоговую структурированную информацию, которую можно использовать для разных целей: анализа данных, создания базы товаров или даже написания своего собственного парсера на языке Python.
Выбор неизвестных заранее тегов
Когда работаем с парсингом сайтов, часто бывает, что структура HTML-кода может меняться в зависимости от разных факторов. Для извлечения информации из таких тегов можно использовать операторы, которые помогут найти нужный элемент на странице. Такой выбор будет осуществляться субъектом парсинга, и, конечно же, для каждого случая может быть свой подход.
Если у нас имеется страница, откуда мы полученного номером, и требуется извлечь информацию, для этого необходимо перейти на сайт-источник. При этом выбор тегов может производиться по вашему усмотрению и согласно соглашению, с которым предоставлен данный сайт. Возможно, вы захотите использовать стандартные теги или же использовать собственные теги согласно статье, скриншоту или другим даным, которые вам нужны.
Для выбора тегов вам необходимо перейти на страницу, задачи которой соответствует ваш запрос. При помощи операторов и методов, которые предлагает вам ваш парсер, можете извлечь данные, которые нужны именно вам. Не стесняйтесь использования различных инструментов для извлечения нужных данных.
Кроме того, возможно, вам понадобится получать адреса страниц для дальнейшего извлечения информации. В этом случае применяется поиск ссылок на другие страницы или даже на js-файлы. Также может быть полезным извлечение информации из удалённых блока. Это всего лишь примеры применения парсеров в различных ситуациях.
Заключение данного раздела заключается в следующем - выбор тегов с использованием операторов и методов зависит от конкретной задачи парсера и поставленных вами целей. Следуйте рекомендациям вашего парсера, изучайте документацию и экспериментируйте с разными вариантами. Главное - уметь анализировать HTML-код и использовать возможности вашего парсера для достижения нужного результата.
Если надо выбрать несколько путей
В процессе разработки парсеров сайтов, возникает ситуация, когда необходимо выбрать несколько путей для обработки данных. Это может быть связано с разными случаями, которые могут возникнуть при работе с различными материалами и сведениями на сайтах.
Когда редко бывает стыдноэто блока с информацией на странице, рубрику которой имеет отдельный редактор, получать данные со страницы соответствует только одному порядку обработки. Но это далеко не всегда.
При заказе разработки парсеров в сервисе info-parser.info, у нас есть наиболее широкий набор настроек, даже для самых сложных случаев. Наш специализированный разработчик, Юзенков Пётр, предоставляет услуги по настройке всего спектра параметров, необходимых для извлечения нужных данных из html-данных сайта.
Услуга настройки парсера включает в себя понадобится практически все настройки, которые могут понадобиться для определения структуры сайта, поиска нужного элемента на странице, извлечения данных из html-файла и многого другого.
При работе с парсером, важным элементом является диапазон действующего сбора данных. Мы можем настроить парсер в соответении с вашими условиями, учитывая ваш запрос и конечные цели. Кроме того, наш парсер может предоставить возможность для вставки оператора range1, который позволяет определить количество данных, которые вы хотели бы получить.
Благодаря соглашению и условиям, которые мы соблюдаем при работе с данными, наши услуги по разработке парсеров максимально упрощают бизнес-процессы наших клиентов. Возможность автоматизировать процессы сбора информации, которые раньше требовали ручной обработки, позволит вам значительно сэкономить время и усилия.
| Настройка | Извлечение полей для конкретного продукта |
|---|---|
| Настройка извлечения ссылок на карточки товаров из категории | Как извлекать значения |
| Настройка пагинаций на английском pagination | Как запускать парсер |
| Что такое grabCatalog формат | Как настроить выгрузку данных в определенный тип файла |
| Краткий Урок-введение в Xpath для парсинга сайтов с примерами | Пример HTML файла |
| Выбор тегов как извлечь конкретные теги через XPath | Предикаты |
| Выбор неизвестных заранее тегов | Процесс парсинга |
В случае, когда вам нужны данные с нескольких страниц сайта, вам понадобится использовать услугу настройки парсера, отличающуюся от стандартных параметров. Также мы можем предоставить рекомендации и консультации оператору для более эффективной и точной настройки парсера.
Мы гарантируем качество нашей работы и работу с данными в соответствии с соглашениями и условиями, установленными с вами.
Заказать разработка парсеров
Переходим к разделу, который раскроет перед нами всю важность заказа разработки парсеров. Даже в современном информационном обществе, многие задачи требуют получения данных, которые находятся на различных страницах и сайтах. Вручную собирать нужные данные может быть долгим и непрактичным образом, а именно поэтому разработка парсеров становится все более актуальной задачей. С помощью парсера, выполненного в соответствии с вашими запросами и задачами, вы можете получить необходимую информацию всего одним кликом.
Исполнитель, занимающийся разработкой парсеров, обладает знаниями и опытом, чтобы создать специальное программное обеспечение, которое имеет все необходимые функции. Разработчик парсера способен настроить его согласно вашим требованиям и позволить вам избежать ручного сбора данных. Этот парсер будет собирать информацию со страниц сайтов, выполнять необходимые операции и предоставлять вам результаты в нужном формате.
Важно отметить, что разработка парсеров имеет широкий функционал, позволяющий собирать данные не только с отдельных страниц, но и с целых категорий и разделов информационных сайтов. Кроме того, парсер может оперировать со ссылками на страницы карточек товаров и производить парсинг информации из них. Таким образом, разработка парсеров дает вам полный контроль над сбором данных в автоматическом режиме без необходимости выполнять трудоемкие процессы вручную.
В результате, заказав разработку парсера, вы получаете инструмент, который выполнит задачу сбора нужных данных в соответствии с вашими требованиями. Это существенно экономит время и усилия, а также позволяет вам сфокусироваться на других задачах. Разработка парсера дает вам право самостоятельно выбирать, какие данные и в каком формате вы получаете. От надежных источников до персонализированных запросов - всё контролируется вами.
Заказывая разработку парсеров, вы получаете не только результаты сбора данных, но и основу для дальнейших манипуляций и аналитики. Разработчик создаст парсер таким образом, чтобы вы могли расширить его функциональность и использовать полученные данные в своих проектах, исследованиях или анализе рынка. Разработка парсеров помогает вам превратить информацию в ценную информацию и решения для вашего бизнеса.
Итак, перейдём к непосредственной разработке и созданию парсера. Для того чтобы посмотреть, как парсится страница и получить данные в нужном формате, можно использовать различные методы и инструменты, такие как ссылки, пагинация, данные, операторы и другие. Базовая настройка парсера обеспечивает его правильное функционирование в соответствии с вашими требованиями и запросами.
Команда разработчиков сопроводит вас на каждом шаге и настроит парсер таким образом, чтобы получить требуемые данные. Они также помогут настроить сбор данных из различных категорий, ссылок на карточки товаров или пагинаций на английском. Импортантно также настроить выгрузку данных в нужный вам формат, чтобы вы могли использовать и анализировать полученные данные дальше.
У разработчиков есть опыт работы с разными сайтами и материалами СМИ, поэтому они знают, как справиться с различными проблемами и сложностями в процессе парсинга. Они помогут вам определить структуру сайта, написать код парсера и провести сам процесс парсинга в соответствии со всеми требованиями и задачами.
Итак, заказ разработки парсеров является неотъемлемой частью современной бизнес-практики. Получение данных становится более эффективным и экономичным процессом, когда задача разработки парсера выполняется профессионалами, которые готовы взять на себя все сложности и непредсказуемые ситуации. Откройте для себя новые возможности парсинга с помощью профессионального разработчика парсеров и раскройте потенциал ваших данных.
Как парсить сайты и материалы СМИ с помощью JavaScript и Nodejs
В данном разделе мы рассмотрим процесс парсинга сайтов и материалов с использованием JavaScript и Nodejs. Как определяется структура сайта-источника, какие инструменты используются для извлечения информации, а также роль JavaScript и Nodejs в этом процессе.
Для начала процесса парсинга необходимо определить структуру сайта и его элементов. Количество и тип элементов зависит от конкретной страницы или раздела, который мы хотим парсить. Для этого пишем специальные функции или шаблоны, которые позволяют извлекать нужные данные с полученного HTML кода страницы.
JavaScript и Nodejs играют важную роль в парсинге. С помощью JavaScript мы можем динамически получать информацию с сайта, в том числе обновлять страницы, производить сортировку и фильтрацию данных. Nodejs позволяет использовать JavaScript на серверной стороне, что делает процесс парсинга более гибким и эффективным.
Для извлечения информации с сайта мы используем различные техники и инструменты. Один из самых распространенных инструментов - Beautiful Soup - позволяет парсить HTML код и извлекать нужные нам данные. Мы можем определить конкретные теги или классы элементов, которые нам интересны, и получить информацию из них.
На следующем этапе мы закрепим полученные знания, расширим функциональность парсера и научимся извлекать информацию из различных категорий или страниц. Для этого мы можем использовать операторы выбора, позволяющие указать необходимые теги и атрибуты для извлечения данных. Также мы можем извлекать ссылки на карточки товаров или другие страницы сайта.
Далеко не все сайты позволяют парсить свои материалы без ограничений. Некоторые сайты могут иметь трансграничную блокировку или использовать специальные js-файлы для защиты данных. В таких случаях важно быть готовым к спорам и иметь возможность адаптировать свой парсер под условия сайта.
В данном разделе мы рассмотрели основные этапы и инструменты парсинга сайтов с помощью JavaScript и Nodejs. Мы изучили процесс определения структуры сайта, извлечения информации и использования различных техник парсинга. Теперь вы готовы приступать к созданию и настройке своего собственного парсера!
Евгений Колесников
Используя свой опыт и компетенцию, Евгений Колесников предлагает возможность получать ценную информацию с помощью разработанного парсера. Благодаря этому инструменту, владельцы сайтов могут собирать необходимые данные и управлять ими в соответствии с требованиями своего бизнеса.
При заказе парсера у Евгения Колесникова, клиент получает возможность настроить сбор информации в соответствии со специфическими требованиями и потребностями. В этом разделе мы переходим к конкретным действиям и настройкам парсера, которые позволяют собирать данные из различных блоков и категорий веб-сайтов.
Евгений Колесников подробно объясняет, как использовать параметры и настройки для извлечения нужных сведений с выбранной страницы или для получения ссылок на определенные категории товаров. Он также дает рекомендации по использованию пагинаций и способам управления данными при парсинге сайтов с разными типами структуры.
В дополнение к этому, Евгений Колесников предоставляет инструкцию по запуску парсера и формату данных, в котором можно сохранять результаты. Он также проводит краткий урок по использованию Xpath для более точного парсинга веб-сайтов и приводит примеры, показывающие, как выбирать и извлекать конкретные теги для получения нужной информации.
Если вы заинтересованы в услугах по парсингу сайтов и получении ценных данных для вашего бизнеса, обратитесь к Евгению Колесникову. Его профессиональный подход и опыт обеспечат успех вашего проекта.
Как устроен парсинг сайтов
Данный раздел рекламного поста посвящен описанию процесса парсинга сайтов и услуг, связанных с этой сферой. Здесь вы сможете узнать о способах сбора данных с сайтов и обработке информации, а также о том, каким образом можно получить удаленные данные. С помощью js-файлов и функций вы сможете проверить работоспособность ссылок и адресов на сайте, а также получить доступ к содержимому веб-страницы и извлечь нужные данные.
Одним из ключевых аспектов парсинга является пагинация, которая регулирует порядок обхода сайта и сбора данных. В зависимости от типа пагинации, парсер переходит по кнопкам или осуществляет бесконечную подгрузку по клику. Это важный момент, который может определять успешность работы скрипта в парсинге страниц сайтов. Кроме того, при выполнении парсинга необходимо учитывать условия использования составленные владельцами сайтов и принимать во внимание сроки действия соглашений.
Основной этап процесса парсинга – обработка тегов. Теги определяют структуру сайта и позволяют получить доступ к конкретной информации. Парсер принимает шаблон, соответствующий структуре сайта, и вставляет в него номера, соответствующие порядку элементов на странице. Затем парсер переходит по ссылкам и извлекает необходимые поля для дальнейшей обработки данных.
Важно отметить, что парсинг сайтов является ответственной деятельностью, требующей согласия владельца сайта. При использовании парсера необходимо соблюдать законодательство и согласовывать свои действия с операторами сайтов. Для предотвращения споров и конфликтов рекомендуется ознакомиться с условиями использования сайта и заключить соглашение с оператором.
Если вы заинтересованы в парсинге сайтов и желаете узнать больше о данной услуге, вам стоит обратиться к профессиональным разработчикам и заказать разработку парсеров. Они смогут предложить вам качественные решения и помочь в настройке парсера для вашего конкретного случая.
Устанавливаем необходимое ПО

Готовы к новым достижениям? Тогда приступим! При создании парсера мы будем использовать программное обеспечение Zennoposter. Zennoposter - это мощный инструмент для автоматизации бизнес-процессов, который позволяет извлекать информацию с веб-страниц и взаимодействовать с различными онлайн-сервисами. Благодаря его функционалу мы сможем удобно и эффективно осуществлять парсинг сайтов и извлекать нужные нам данные, такие как информация о товарах и материалах СМИ.
Для начала, перейдём на официальный сайт Zennoposter и скачаем установочный файл. После скачивания запустим его и следуя инструкциям установщика выполним установку программы на своем компьютере.
После установки откроем программу и перейдем к настройкам. Во вкладке "Настройки" укажем все необходимые данные для доступа к интернету, такие как настройки прокси, данные для авторизации на сайтах и другие параметры, которые могут понадобиться в процессе парсинга.
Теперь, когда все необходимые настройки выполнены, давайте приступим к созданию нашего первого парсера. Для этого откроем встроенный в Zennoposter редактор и напишем код парсера, который будет извлекать информацию с веб-страницы. С помощью Zennoposter мы сможем выбирать нужные нам элементы, такие как теги и ссылки, и извлекать из них нужные сведения.
Процесс парсинга осуществляется по шагам. Сначала мы определяем структуру сайта, исследуя его содержимое. Затем при помощи XPath, мощного языка запросов, мы выбираем конкретные теги и элементы страницы, где находится нужная нам информация. При необходимости, мы также можем использовать предикаты, что позволяет нам выбирать неизвестные заранее теги. Если на одной странице находится несколько путей к извлекаемым данным, мы можем выбрать наиболее подходящий для нас.
Для большего понимания процесса парсинга, представим пример HTML-файла. В нем мы сможем выбрать нужные нам теги, используя XPath. Однако важно отметить, что каждая страница может иметь свою уникальную структуру, поэтому мы должны внимательно анализировать исходный код страницы.
Подходящие теги могут быть выбраны с использованием различных методов, таких как клик по элементу или переход по ссылкам. Мы можем настроить парсер для извлечения полей для конкретных продуктов или для поиска ссылок на карточки товаров из категории.
Не забывайте о настройке пагинаций - способов перехода между страницами, которые позволят нам выгрузить все необходимые данные. Мы можем настроить пагинацию для страниц на английском языке и указать параметры, по которым будет осуществляться переход между страницами.
Важно отметить, что после настройки парсера мы должны сохранить данные в нужном нам формате файла. Благодаря Zennoposter мы можем настроить выгрузку данных в определенный тип файла, что упростит дальнейшую обработку собранных данных.
Элементы, которые мы сможем извлечь при помощи парсера, будут зависеть от конкретных целей, которые у нас возникли для этой задачи. Имейте в виду, что мы можем анализировать не только текстовую информацию, но и изображения, видео и другие медиа-элементы.
Следует отметить, что в нашем процессе парсинга сайтов мы уделяем внимание важнейшим аспектам, таким как безопасность и соблюдение соглашений об использовании информации с сайта. Мы рекомендуем быть внимательными и уважительными к владельцам сайтов, с которыми мы взаимодействуем. Обратите внимание на сведения о доступе к информации на сайте и правилах использования, изложенных на странице.
Важно также учесть, что эффективность парсинга может варьироваться в зависимости от разных факторов, таких как скорость интернет-соединения и сложность сайта, с которым мы взаимодействуем. Большую роль в этом процессе играют также операторы и ресурсы компьютера, на котором работает парсер.
Парсим сайт с первым типом пагинации отдельные страницы переход по кнопке
В этом разделе рассмотрим процесс парсинга сайта с использованием первого типа пагинации, где для перехода на отдельные страницы необходимо нажатие на кнопку. Мы предоставим вам срок, в течение которого выполним данную задачу, исключив ручное переключение между страницами. Вам достаточно предоставить ссылку на сайт, который требуется спарсить, и мы сделаем все остальное.
Для начала, наша команда разработчиков создаст скрипт, который будет автоматически переходить между страницами. Мы используем передовые технологии, такие как URLSearchParams и оператор нажатия, чтобы удалённо управлять этим процессом. Используя блок кода, из которого можно извлечь необходимые данные, мы сделаем парсинг информации с каждой страницы.
Полученные данные будут сохранены в структурированном формате, который будет отвечать вашим потребностям. Мы гарантируем, что вся информация будет предоставлена в удобочитаемом виде и содержать только те данные, которые вам необходимы. В процессе разработки парсера мы учтем все ваши требования и пожелания.
Также, вам будет предоставлен пользовательский интерфейс, который позволит вам легко управлять полученными данными. Благодаря нашей разработке вы будете иметь возможность контролировать процесс парсинга из любого удобного для вас места, даже находясь далеко от офиса. Информация будет предоставлена в удобном для вас формате, таком как HTML, благодаря чему вы сможете воспользоваться ею в том виде, который вам удобен.
Обратите внимание, что наша команда работает с разными типами страниц и субъектов парсинга. Мы имеем опыт в разработке парсеров для различных информационных ресурсов, включая действующие сайты в разных отраслях. Мы гарантируем, что ваш сайт будет спарсен полностью и вы получите всю необходимую информацию для вашего бизнеса.
| Пример кода: | beautifulSoup(html_code, "html.parser") |
| Пример файла: | fs.appendFileSync("путь/articles.html", информация, "utf-8") |
Мы предоставляем полную разработку парсера от момента заказа до получения полностью функционирующего парсера. Все работы проводятся нашими экспертами с многолетним опытом разработки парсеров. Мы гарантируем высокую производительность и качество работы нашего продукта. Закажите разработку парсеров у нас сегодня и получите все необходимые данные для вашего бизнеса.
Определение структуры сайта
Перед тем как приступить к парсингу, необходимо определить, где на странице находится нужная нам информация. Для этого мы будем использовать инструменты, такие как редактор кода и инспектор элементов браузера.
Вам потребуется открыть веб-страницу в режиме разработчика и изучить ее HTML-код. В этом коде будут содержаться все необходимые нам данные. Обратите внимание на разметку страницы и поищите теги, содержащие информацию, которую вы хотите извлечь.
Для нахождения нужных тегов удобно использовать XPath – язык запросов, который позволяет выбрать нужные элементы на основе их иерархической структуры. Для этого вы можете воспользоваться оператором '//', который выбирает все узлы документа, соответствующие заданному пути.
Теперь, когда мы определили структуру сайта и нашли необходимые теги, мы можем приступить к созданию парсера. Для этого мы используем язык программирования, например Python, и библиотеку для парсинга веб-страниц, например BeautifulSoup.
Сначала мы соберем HTML-код страницы, с которой хотим извлекать информацию. Для этого можно использовать функции библиотеки BeautifulSoup или другого инструмента для загрузки веб-страницы.
После получения HTML-данных мы будем использовать ранее найденные теги и XPath-запросы, чтобы извлечь нужную информацию. Для этого мы пройдемся по HTML-данным и выполним операции, которые позволят нам получить необходимые значения.
Если для получения данных требуется переход на другую страницу или выполнение других действий, мы можем использовать различные функции и операторы, такие как нажатие на кнопку или переход по ссылке. Каждый оператор будет настроен в соответствии с требованиями и структурой сайта.
После успешного выполнения этих операций, результат может быть сохранен в файл, который можно использовать в дальнейшем для обработки данных или анализа.
Важно отметить, что работа с парсером сайта должна осуществляться в соответствии с правилами использования информации, установленными владельцем сайта или в соответствии с договором-офертой, если таковой имеется.
Если у вас есть вопросы или вам нужна помощь в создании парсера, наши специалисты всегда готовы помочь вам, обращайтесь!
Пишем код парсера
В этом разделе рассмотрим этап разработки кода парсера для обработки и получения данных с указанной страницы. После перехода на нужную страницу будет использоваться редактор кода для написания скрипта парсера, который будет отвечать за получение и обработку необходимых данных.
Для начала процесса разработки нам понадобится инструмент URLSearchParams для получения страницы по URL. Затем мы приступим к написанию кода в редакторе, который будет обрабатывать данные с указанной страницы.
Основываясь на принятых соглашениях и правах доступа, необходимо указать поля и элементы, которые нужны для получения результата. Также важно учесть пользовательское соглашение и пользовательские настройки, чтобы код был наиболее гибким и подходил для разных случаев.
После получения нужных данных, полученные результаты могут быть сохранены в определенный файл, используя функцию fs.appendFileSync с указанным путем articles.html. Это позволяет сохранить данные для дальнейшей обработки или предоставления заказчику.
Разработка парсера требует внимания к деталям, таким как правильное нахождение и обработка элемента на странице, а также правильное использование HTML-тегов и атрибутов. При каждом процессе парсинга важно учесть договора-оферты и соблюдать права доступа к странице, чтобы не нарушать платформу.
Код парсера можно использовать как основу для дальнейшей разработки и настройки, позволяя получить нужные данные с каждой страницы. Этот процесс является важной частью парсинга и может быть использован для разных целей, включая получение информации социального характера, аналитических целей и многого другого.
Подключив данный код к парсеру, мы получим возможность перейти на страницу, на которой находится нужная нам информация. Это позволит извлечь нужные данные для дальнейшей обработки, а также предоставить полезные сведения заказчику.
Код парсера, который мы разрабатываем, может быть использован для получения данных с разных сайтов и поможет в различных задачах, в том числе и для анализа данных. Перейдем к конкретным шагам разработки парсера и извлечения данных.
Процесс парсинга
В этом разделе мы рассмотрим процесс парсинга сайтов с помощью разработанного ранее парсера. Мы приступим к извлечению необходимой информации, которая соответствует нашим целям и требованиям.
На этапе разработки мы уже создали парсер, способный получать сырой текст с сайтов. Теперь наша задача заключается в обработке этого текста и извлечении нужных данных.
Перед началом парсинга мы должны выбрать адреса всех страниц, которые будут парситься. Это может быть определенная страница сайта или же категория сайта, содержащая информацию, которую мы хотим извлечь.
При выполнении парсинга мы используем различные методы обработки текста, такие как чистка текста от ненужных символов или шаблонов, а также сбор функций для извлечения конкретных полей. Для работы с текстом мы можем использовать библиотеки, такие как BeautifulSoup или соответствующие функции и операторы языка Python.
После обработки текста мы переходим к извлечению информации. Мы определяем структуру сайта и выбираем теги, в которых находится нужная нам информация. Это может быть текст, ссылки или другие элементы.
Одной из ключевых частей парсинга является работа с пагинациями. В зависимости от наличия пагинации на сайте, мы настраиваем парсер для получения всех данных, включая информацию с разных страниц.
В процессе работы парсера мы можем использовать функции или запросы для дальнейшего раскрытия нужной информации или доступа к страницам. Это может включать переходы по ссылкам или вставку параметров в URL-адрес.
В условиях, когда парсинг производится на большом количестве сайтов, наш парсер может быть настроен для работы в разных случаях и с разными типами сайтов. Мы должны гибко настраивать функцию парсера и учитывать особенности каждого из них.
Когда все необходимые данные успешно извлечены и обработаны, мы можем сохранить их в определенный файл или использовать по нашему усмотрению. Это может быть файл в виде таблицы или любой другой тип файла, который соответствует нашим потребностям.
Таким образом, процесс парсинга сайтов состоит из нескольких этапов: от разработки парсера и выбора адресов страниц, до обработки текста и извлечения нужных данных с использованием функций и инструментов парсинга. Важно учесть особенности каждого сайта и настроить парсер соответствующим образом для достижения желаемых результатов.
Парсим сайт со вторым типом пагинации бесконечная подгрузка по клику
Для того чтобы осуществить парсинг сайта с такой пагинацией, мы сначала определяем структуру сайта и находим js-файл, отвечающий за подгрузку нового контента. Затем мы пишем код парсера, который будет эмулировать нажатие на кнопку или выполнение JavaScript-кода, чтобы получить дополнительные данные. При этом важно учитывать права и условия использования сайта-источника и получить согласие заказчика на парсинг его собственности.
Во время парсинга сайта с этим типом пагинации мы можем использовать различные методы для определения количества элементов, подгружаемых по клику. Например, мы можем анализировать изменение количества элементов в коде страницы или использовать специальные HTML-атрибуты для мониторинга процесса подгрузки.
Парсинг сайта со вторым типом пагинации является востребованным инструментом для автоматизации бизнес-процессов и получения актуальных данных с различных интернет-ресурсов. Однако, необходимо учитывать права и условия предоставления данных, чтобы избежать споров и конфликтов, возникающих при нарушении авторских прав и ограничений доступа.
Если вы заинтересованы в разработке парсера для сайта с вторым типом пагинации, мы рады предложить наши услуги. Мы имеем опыт в создании парсеров разных сложностей и можем выполнить задачу в кратчайшие сроки. Подключившись к вашему бизнесу, мы сделаем все необходимое для парсинга выбранного сайта и получения нужного содержимого.
Ничто не вечно
В бизнес-процессах современного мира важно быть гибкими и адаптироваться к постоянно меняющимся требованиям рынка. Особенно это касается обработки и сбора информации. В один момент процесс может работать идеально, а в следующий момент структура сайта или формат данных может измениться. В таких случаях необходимо иметь инструмент, который позволяет быстро и эффективно адаптироваться к новым условиям.
Именно в этом контексте парсинг сайтов становится неотъемлемой частью бизнес-процессов. Парсер – это программа, способная автоматически обрабатывать и извлекать нужную информацию со страниц сайтов. При помощи парсеров можно собирать данные с сайтов, анализировать их, и использовать в своих целях: от получения конкурентной информации до сбора данных для аналитической работы и принятия важных решений.
Итак, что такое парсер сайта?
Парсер сайта – это инструмент, позволяющий автоматически обрабатывать веб-страницы и извлекать из них нужные данные. Это особенно полезно, когда требуется обработать большое количество страниц, так как ручной сбор данных был бы неэффективным и затратным по времени процессом.
С помощью парсера вы можете получить все необходимые данные со страниц сайта, такие как названия товаров, цены, описания, артикулы и т.д. При этом можно избежать ручного копирования и вставки, что исключает риск ошибок и экономит время.
Как это работает?
Парсеры работают по принципу запрос-ответ. Они отправляют запросы на страницы сайтов, получают их в ответ и затем обрабатывают полученный HTML-код. С помощью специальных инструментов, таких как XPath, парсеру указываются конкретные элементы на странице, которые нужно извлечь и сохранить.
Что можно сделать с помощью парсера?
Возможности парсера огромны. С их помощью можно собирать информацию о товарах с конкурентных сайтов, отслеживать цены на рынке, получать данные о запасах и скидках, анализировать отзывы и рейтинги, определять актуальность информации и многое другое.
Вы также можете использовать парсеры для определения структуры сайта, извлечения ссылок и адресов страниц, а также для автоматического сбора информации по заданным критериям.
Важно помнить, что при использовании парсера необходимо соблюдать законы и правила, согласно которым собранная информация будет использоваться. Сбор персональных данных и нарушение авторских прав запрещены и могут влечь за собой юридические последствия.
Теперь у вас есть возможность научиться «парсить» сайты и собирать необходимые данные для своего бизнеса или аналитической работы. Читайте статьи, смотрите видео-инструкции и применяйте полученные знания в своей работе. Парсинг сайтов – это мощный инструмент, который может быть полезен в различных сферах деятельности.
Разнообразьте свои бизнес-процессы, автоматизируйте сбор и обработку данных, и ваши решения будут приниматься на основе актуальной и достоверной информации.
Заключение
В экспоненциально растущем мире информации существует потребность в трансграничной работе с различными источниками данных, включая веб-сайты. Именно поэтому освоение парсинга сайтов является актуальной и необходимой навыков современного человека.
Переходим к самому процессу парсинга. Одним из наиболее важных моментов является определение структуры сайта и выбор информации, которую необходимо извлечь. Для этого используется язык разметки HTML, поэтому хорошее владение и понимание HTML-данных поможет в получении желаемых результатов.
При разработке парсера необходимо учитывать настройки сайта-источника и соблюдать соглашение об использовании данных, чтобы не нарушать права субъекта информации и не нарушать соглашение с оператором сайта.
Одним из способов получения информации является использование XPath, который позволяет выбирать конкретные теги на веб-странице. Для этого необходимо определить структуру HTML и понимать, какие теги содержат нужную информацию.
Необходимо также учитывать различные типы пагинации, которые могут применяться на сайтах. В зависимости от типа пагинации, расположение информации на странице может различаться, а также способ загрузки дополнительных данных может отличаться (например, по нажатию кнопки или при бесконечной подгрузке).
Важно отметить, что использование парсера должно соответствовать согласию субъекта информации и не нарушать законодательство. Данный инструмент должен использоваться для законных целей, а полученные данные должны быть обработаны с учетом прав субъекта информации.
Настоящий раздел подробно рассмотрел процесс написания парсера, уделил внимание настройкам и способам извлечения данных, а также представил примеры использования XPath для выбора неизвестных заранее тегов и обработки различных типов пагинации.
Освоение данной темы позволит формировать самостоятельные настройки парсера, получать необходимую информацию с веб-страниц и сохранять ее в определенном формате файла. Таким образом, у вас будет возможность эффективно работать с данными с различных сайтов.
Начинайте изучать и применять парсинг сайтов прямо сейчас, чтобы расширить свои навыки и достичь новых результатов в области работы с информацией в Интернете!